
FFmpeg:数字多媒体处理的终极指南
FFmpeg:数字多媒体处理的终极指南
引言:数字时代的炼金术
在人类文明的长河中,信息的记录与传播始终是推动社会进步的核心动力。从远古时期的洞穴壁画,到活字印刷术的发明,再到现代的数字媒体,我们不断寻求更高效、更生动的方式来表达和分享思想。进入21世纪,数字多媒体——音频、视频、图像——已成为我们日常生活中不可或缺的信息载体。然而,这些看似简单的音视频文件背后,隐藏着一个极其复杂的技术生态系统。在这个生态系统中,有一个工具,它如同数字世界的瑞士军刀,几乎无所不能,它就是FFmpeg。
FFmpeg的故事始于一个法国学生Fabrice Bellard的业余项目,如今已发展成为全球最强大、最广泛使用的开源多媒体框架之一。它不仅仅是一个软件,更是一个庞大的技术集合,一个数字多媒体处理的完整解决方案。从YouTube、Netflix到VLC媒体播放器,从智能手机到超级计算机,FFmpeg的身影无处不在,默默支撑着现代数字媒体的运行。
为什么我们需要深入理解FFmpeg?因为在这个多媒体内容爆炸的时代,掌握FFmpeg意味着掌握了数字媒体的核心技术。它允许我们理解、转换、处理和创造几乎任何形式的音视频内容。无论你是想将一部电影转换为适合手机观看的格式,还是想实现一个实时视频流媒体服务,抑或是想开发一个全新的视频编解码器,FFmpeg都提供了必要的工具和库。
本章将带领读者踏上一段深入FFmpeg核心的旅程。我们将从其基本架构开始,逐步探索其内部工作原理,理解其设计哲学,掌握其使用技巧,并最终能够像专家一样运用这个强大的工具。这不仅仅是一个技术教程,更是一次对数字多媒体处理本质的探索。正如炼金术士追求将铅转化为黄金,FFmpeg让我们能够将原始的数字数据转化为丰富多彩的多媒体体验。
FFmpeg的架构与设计哲学
宏观视角:一个完整的生态系统
FFmpeg并非单一程序,而是一个由多个组件构成的复杂生态系统。要真正理解FFmpeg,我们必须首先理解其整体架构。FFmpeg的设计哲学可以概括为"模块化、可扩展、高性能",这三个原则贯穿于其每一个组件的设计之中。
FFmpeg生态系统主要由以下几个核心部分组成:
- libavcodec:编解码器库,负责音频和视频的编码与解码。
- libavformat:格式处理库,负责多媒体容器格式的解析与生成。
- libavutil:通用工具库,提供各种基础功能,如数据结构、数学运算、加密等。
- libavfilter:滤镜库,提供音频和视频处理的各种滤镜效果。
- libswscale:色彩空间转换和图像缩放库。
- libswresample:音频重采样库。
- ffmpeg:命令行工具,FFmpeg的前端接口。
- ffplay:简单的媒体播放器。
- ffprobe:媒体分析工具。
这种模块化设计使得FFmpeg具有极高的灵活性和可扩展性。每个库都可以独立使用,也可以组合使用以完成复杂的多媒体处理任务。例如,一个简单的视频转码任务可能需要同时使用libavformat(解析输入文件)、libavcodec(解码视频)、libswscale(调整分辨率)、libavcodec(重新编码视频)和libavformat(生成输出文件)。
深度探索:FFmpeg的内部工作流程
为了更深入地理解FFmpeg的工作原理,让我们跟随一个典型的视频转码任务,探索FFmpeg的内部工作流程。假设我们要将一个MP4文件转换为AVI文件,并调整视频分辨率。
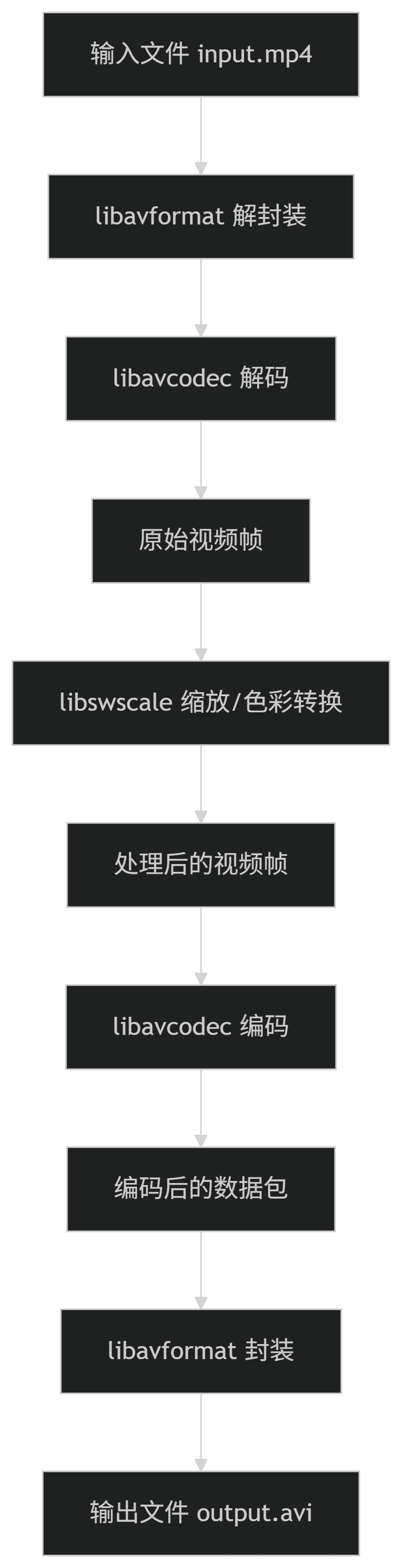
这个过程可以分解为以下几个关键步骤:
- 解封装(Demuxing):FFmpeg首先使用libavformat库打开输入文件,解析其容器格式(如MP4),从中提取出音频和视频的基本数据流(Elementary Streams)。这一步就像是打开一个包裹,取出里面的物品。
- 解码(Decoding):提取出的编码数据包(Packet)被送入libavcodec库进行解码。对于视频流,这意味着将压缩的H.264或HEVC等编码数据转换为原始的YUV或RGB像素数据;对于音频流,则是将AAC或MP3等编码数据转换为PCM样本。
- 处理(Processing):解码后的原始数据可以经过各种处理。在我们的例子中,视频帧被送入libswscale库进行分辨率调整和可能的色彩空间转换。此外,还可以应用libavfilter中的各种滤镜,如去噪、锐化、色彩校正等。
- 编码(Encoding):处理后的原始数据被送入libavcodec库进行重新编码。这一步将大量的原始数据压缩为更小的编码数据包,以便存储和传输。编码过程涉及复杂的算法,如运动估计、离散余弦变换、量化等。
- 封装(Muxing):最后,编码后的数据包被送入libavformat库,按照目标容器格式(如AVI)的要求进行封装,生成最终的输出文件。
这个看似简单的过程背后,隐藏着极其复杂的技术细节。每一个步骤都涉及大量的算法优化、内存管理和错误处理。FFmpeg的卓越之处在于,它将这种复杂性隐藏在简洁的API和命令行接口之后,使得用户可以轻松完成复杂的多媒体处理任务。
设计哲学:效率与灵活性的平衡
FFmpeg的设计哲学体现了开源软件工程的精髓。它不仅仅是一个功能强大的工具集,更是一个精心设计的软件架构案例。让我们深入探讨其核心设计原则:
1. 模块化与解耦
FFmpeg的每个库都专注于特定的功能领域,并通过清晰的接口与其他库交互。这种模块化设计带来了几个关键优势:
- 可维护性:每个库可以独立开发和维护,降低了系统的复杂性。
- 可扩展性:新的编解码器、格式或滤镜可以作为插件添加,无需修改核心代码。
- 灵活性:用户可以根据需要选择使用特定的库,而不是被迫使用整个FFmpeg套件。
例如,如果你只需要处理音频格式,可以只使用libavformat和libavcodec,而不需要引入视频处理相关的库。
2. 抽象与统一接口
FFmpeg通过精心设计的抽象层,统一了各种不同编解码器和格式的接口。无论你处理的是H.264视频还是AAC音频,是MP4容器还是MKV容器,FFmpeg都提供了一致的API。这种设计使得开发者可以编写通用的多媒体处理代码,而不需要关心底层格式的具体细节。
以编解码器为例,FFmpeg定义了一个通用的 AVCodec结构,所有具体的编解码器实现(如H.264解码器、AAC编码器等)都遵循这个接口。当需要解码一个视频帧时,无论其编码格式如何,都可以使用相同的API调用:
// 伪代码示例
AVCodec *codec = avcodec_find_decoder(stream->codecpar->codec_id);
AVCodecContext *codec_ctx = avcodec_alloc_context3(codec);
avcodec_open2(codec_ctx, codec, NULL);
// 解码循环
while (av_read_frame(format_ctx, &packet) >= 0) {
if (packet.stream_index == video_stream_index) {
avcodec_send_packet(codec_ctx, &packet);
while (avcodec_receive_frame(codec_ctx, frame) == 0) {
// 处理解码后的帧
}
}
}
这种抽象设计极大地简化了多媒体应用程序的开发,使得开发者可以专注于业务逻辑,而不是陷入各种格式的细节中。
3. 性能优化
FFmpeg从诞生之初就将性能作为核心设计目标。多媒体处理,特别是视频编解码,是计算密集型任务,对性能要求极高。FFmpeg通过多种技术手段实现了卓越的性能:
- 汇编优化:对于关键算法,FFmpeg提供了针对不同CPU架构(如x86、ARM)的手工汇编优化代码。这些优化代码利用了特定CPU的SIMD指令集(如MMX、SSE、AVX、NEON等),可以显著提高处理速度。
- 多线程处理:FFmpeg支持多线程编解码和处理,可以充分利用现代多核CPU的计算能力。例如,视频解码可以并行处理多个帧,滤镜图可以并行执行多个滤镜。
- 零拷贝设计:FFmpeg尽可能减少数据在内存中的拷贝操作。例如,在解封装后,数据包可以直接传递给解码器,而不需要额外的拷贝。这种设计减少了内存带宽的消耗,提高了处理效率。
- 硬件加速:FFmpeg支持利用GPU、专用媒体处理器等硬件加速多媒体处理。通过API如VA-API、VDPAU、DXVA2、VideoToolbox等,FFmpeg可以将部分计算密集型任务(如运动补偿、IDCT等)卸载到硬件,大幅提高性能。
4. 跨平台兼容性
FFmpeg支持几乎所有主流的操作系统和CPU架构,包括Windows、Linux、macOS、BSD、Android、iOS等。这种广泛的兼容性使得FFmpeg成为跨平台多媒体应用的首选解决方案。
为了实现这种跨平台兼容性,FFmpeg采用了以下策略:
- 条件编译:使用预处理器指令根据目标平台选择性地编译特定代码。
- 抽象层:为平台特定功能(如线程、网络、硬件加速)提供统一的抽象接口。
- 构建系统:使用复杂的构建系统(如Makefile、CMake)自动检测目标平台的特性并相应地配置编译选项。
这种跨平台设计使得开发者可以编写一次代码,然后在多个平台上运行,大大降低了开发和维护成本。
历史演进:从个人项目到全球标准
FFmpeg的发展历程是开源软件成功的一个典型案例。了解其历史演进有助于我们理解其设计决策和技术选择。
起源(2000-2004)
FFmpeg项目始于2000年,由法国程序员Fabrice Bellard发起。最初的版本只包含一个简单的命令行工具,能够解码一些基本的视频格式。Bellard以其卓越的编程能力和对多媒体格式的深刻理解,为项目奠定了坚实的基础。
2001年,Bellard发布了FFmpeg 0.4.6版本,这个版本已经能够解码多种视频格式,并开始支持编码功能。同年,Michael Niedermayer加入项目,并很快成为项目的核心维护者。
快速发展(2004-2010)
在这一阶段,FFmpeg的功能迅速扩展,支持的格式和编解码器数量大幅增加。2004年,FFmpeg 0.4.9-pre1版本发布,引入了libavformat和libavcodec库,标志着FFmpeg从单一工具向库集合的转变。
2007年,FFmpeg项目经历了一次重大分裂。由于社区内部的管理分歧,一部分开发者分叉出了Libav项目。这次分裂虽然导致了开发资源的分散,但也促进了两个项目之间的竞争和创新。
成熟与普及(2010-至今)
2010年后,FFmpeg进入了成熟期。尽管与Libav的竞争持续了几年,但FFmpeg凭借其更活跃的开发社区和更广泛的支持,逐渐成为主导项目。2015年,Libav项目基本停止开发,大部分功能被重新合并回FFmpeg。
在这一阶段,FFmpeg的稳定性和性能得到了显著提升,支持的编解码器和格式几乎涵盖了所有已知的媒体标准。同时,FFmpeg的API也逐渐稳定,成为许多商业和开源多媒体应用的基础。
今天,FFmpeg已经成为事实上的多媒体处理标准,被广泛应用于视频网站、流媒体服务、视频编辑软件、媒体播放器等众多领域。其成功不仅在于技术上的卓越,更在于其开放的开发模式和活跃的社区支持。
FFmpeg的核心组件详解
libavformat:多媒体格式的通用解析器
在数字多媒体的世界中,文件格式(容器格式)扮演着至关重要的角色。它们就像是包裹,将音频、视频、字幕等多种数据流组织在一起,并提供了同步、元数据等关键信息。libavformat(通常简称为lavf)是FFmpeg中负责处理这些容器格式的库,它支持几乎所有已知的多媒体格式,包括MP4、MKV、AVI、MOV、FLV、WebM等。
容器格式的内部结构
要理解libavformat的工作原理,我们首先需要了解容器格式的基本结构。虽然不同的容器格式在细节上有所不同,但它们通常遵循一些共同的原则:
- 文件头(Header):包含文件的元数据,如创建时间、持续时间、码率、所包含的流信息等。
- 索引(Index):提供文件中各个数据包的位置信息,支持随机访问。
- 数据包(Packet):包含实际的编码数据,每个数据包通常对应一个视频帧或一段音频。
- 文件尾(Trailer):某些格式(如MP4)在文件末尾包含额外的元数据或索引。
libavformat通过解析这些结构,将容器格式中的各种数据流提取出来,供后续处理使用。
核心数据结构
libavformat定义了几个关键的数据结构,用于表示多媒体文件和其中的数据流:
// 格式上下文,表示一个多媒体文件
typedef struct AVFormatContext {
const AVClass *av_class; // AVClass类,用于日志和选项
struct AVInputFormat *iformat; // 输入格式
struct AVOutputFormat *oformat; // 输出格式
void *priv_data; // 格式私有数据
AVIOContext *pb; // I/O上下文
unsigned int nb_streams; // 流的数量
AVStream **streams; // 流数组
char filename[1024]; // 文件名
int64_t duration; // 持续时间(以AV_TIME_BASE为单位)
int bit_rate; // 总比特率
AVDictionary *metadata; // 元数据
// ... 其他字段
} AVFormatContext;
// 流,表示文件中的一个音频、视频或字幕流
typedef struct AVStream {
int index; // 流索引
AVCodecContext *codec; // 编解码器上下文(已弃用)
AVCodecParameters *codecpar; // 编解码器参数
AVRational time_base; // 时间基准
int64_t start_time; // 起始时间
int64_t duration; // 持续时间
AVDictionary *metadata; // 流特定的元数据
AVRational avg_frame_rate; // 平均帧率(仅视频)
// ... 其他字段
} AVStream;
// 数据包,包含一个编码后的数据单元
typedef struct AVPacket {
AVBufferRef *buf; // 引用计数的缓冲区
int64_t pts; // 显示时间戳
int64_t dts; // 解码时间戳
uint8_t *data; // 数据指针
int size; // 数据大小
int stream_index; // 所属流的索引
int flags; // 标志位
// ... 其他字段
} AVPacket;
这些结构体构成了libavformat的核心API。通过它们,应用程序可以打开多媒体文件,查询其属性,读取其中的数据包,以及创建新的多媒体文件。
解封装与封装过程
libavformat的主要功能可以分为两大类:解封装(Demuxing)和封装(Muxing)。解封装是从容器格式中提取数据流的过程,而封装则是将数据流写入容器格式的过程。
解封装过程:
解封装过程的基本步骤如下:
- 打开输入文件:使用
avformat_open_input()函数打开多媒体文件。这个函数会读取文件头,自动检测文件格式,并初始化AVFormatContext结构。 - 查询流信息:对于某些格式(如MPEG-TS),流信息可能分布在文件的各个部分。使用
avformat_find_stream_info()函数可以读取足够的文件内容,以获取所有流的详细信息。 - 读取数据包:使用
av_read_frame()函数循环读取文件中的数据包。每次调用都会返回一个AVPacket结构,包含一个编码后的数据单元(如一个视频帧或一段音频)。 - 关闭文件:处理完成后,使用
avformat_close_input()函数关闭文件并释放资源。
封装过程:
封装过程的基本步骤如下:
- 创建输出上下文:使用
avformat_alloc_output_context2()函数创建一个AVFormatContext结构,用于表示输出文件。 - 添加流:使用
avformat_new_stream()函数为输出文件添加流(视频、音频等),并设置每个流的参数,如编解码器类型、时间基准等。 - 打开输出文件:使用
avio_open()函数创建或打开输出文件,并写入文件头。 - 写入数据包:使用
av_interleaved_write_frame()或av_write_frame()函数将编码后的数据包写入文件。这些函数会处理数据包的时间戳和交织(将不同流的数据包按时间顺序排列)。 - 写入文件尾:所有数据包写入完成后,使用
av_write_trailer()函数写入文件尾(如果格式需要),并关闭文件。
时间戳处理
时间戳处理是libavformat中最复杂也最关键的部分之一。在多媒体文件中,每个数据包都有一个或多个时间戳,用于指示其显示或解码的时间。libavformat使用以下几种时间戳:
- PTS(Presentation Time Stamp):显示时间戳,指示数据包应该显示的时间。
- DTS(Decoding Time Stamp):解码时间戳,指示数据包应该解码的时间。
- Duration:数据包的持续时间。
对于某些编解码器(如MPEG视频),解码顺序和显示顺序可能不同。例如,B帧(双向预测帧)需要在其后的帧解码后才能显示,因此其DTS会早于PTS。libavformat负责处理这些复杂的时间戳关系,确保数据包以正确的顺序传递给解码器。
时间戳通常以 AVStream的 time_base为单位表示。time_base是一个有理数(分子和分母),表示时间的基本单位。例如,如果 time_base为1/90000,则时间戳90000表示1秒。
格式探测与自动检测
libavformat的一个强大功能是能够自动检测多媒体文件的格式。当使用 avformat_open_input()打开文件时,libavformat会尝试以下方法来确定文件格式:
- 通过文件扩展名:首先检查文件扩展名(如.mp4、.mkv),如果扩展名已知且可靠,则直接使用对应的格式。
- 通过文件头:如果扩展名不可靠或不存在,libavformat会读取文件的前几个字节,与已知格式的特征(称为"magic number")进行匹配。
- 通过内容分析:对于某些格式(如MPEG-TS),可能需要分析更多的文件内容才能确定格式。
这种自动检测机制使得应用程序可以处理几乎任何多媒体文件,而无需预先知道其格式。
网络协议支持
除了本地文件,libavformat还支持多种网络协议,包括HTTP、HTTPS、RTSP、RTMP、HLS、DASH等。这使得FFmpeg可以直接从网络流中读取数据,或将数据写入网络流。
网络协议的支持通过 AVIOContext结构实现,它提供了一个统一的I/O接口,抽象了底层的数据源(文件、网络等)。例如,要从RTSP流中读取数据,只需将URL传递给 avformat_open_input(),libavformat会自动选择合适的协议处理程序。
错误处理与恢复
多媒体文件可能因为各种原因(如网络中断、存储损坏、格式错误等)而损坏。libavformat提供了多种机制来处理这些错误:
- 错误检测:libavformat会检测格式错误,如无效的文件头、损坏的数据包等,并返回相应的错误代码。
- 错误恢复:对于某些可恢复的错误(如丢失的数据包),libavformat会尝试跳过错误部分,继续处理后续数据。
- 错误回调:应用程序可以注册错误回调函数,在发生错误时执行自定义处理逻辑。
- 日志系统:libavformat提供了详细的日志系统,可以帮助开发者诊断问题。
libavcodec:编解码器的宇宙
如果说libavformat是FFmpeg的骨架,那么libavcodec(通常简称为lavc)就是其心脏。这个库负责处理音频和视频的编码与解码,支持了数百种编解码器,从古老的MPEG-1到最新的AV1,从简单的PCM到复杂的Opus。libavcodec是FFmpeg中最复杂、最核心的组件,也是其性能优势的主要来源。
编解码基础理论
在深入libavcodec的实现细节之前,我们需要先理解一些编解码的基础理论。编解码(Codec)是编码器(Encoder)和解码器(Decoder)的合称,负责将原始的音频或视频数据压缩为更小的编码数据,或将编码数据解压缩为原始数据。
视频编解码原理:
视频编解码的核心挑战在于如何在有限的比特率下保持尽可能高的视觉质量。现代视频编解码器通常采用以下技术:
- 预测编码:利用视频帧之间的时间相关性(运动补偿)和帧内的空间相关性(帧内预测)来减少冗余信息。
- 变换编码:将预测残差(实际像素与预测像素的差值)从空间域转换到频率域(通常使用离散余弦变换DCT或其变种),使能量集中在少数低频系数上。
- 量化:减少变换系数的精度,丢弃人眼不敏感的高频信息,这是有损压缩的主要来源。
- 熵编码:使用变长编码(如霍夫曼编码)或算术编码对量化后的系数和辅助信息进行无损压缩,进一步减少数据量。
- 环路滤波:在解码端应用滤波器,减少压缩引入的块效应和振铃效应,提高视觉质量。
音频编解码原理:
音频编解码的目标与视频类似,但在技术实现上有所不同:
- 变换编码:将时域音频信号转换到频域(通常使用改进的离散余弦变换MDCT),利用人耳对某些频率不敏感的特性。
- 心理声学模型:根据人耳的听觉特性(如掩蔽效应),决定哪些频率成分可以丢弃或粗略表示。
- 量化与熵编码:与视频编解码类似,对频域系数进行量化和熵编码。
- 立体声编码:利用左右声道之间的相关性,使用联合立体声技术(如中/侧编码)提高压缩效率。
libavcodec的架构设计
libavcodec的架构设计体现了高度的抽象和模块化。它定义了一套统一的编解码器接口,使得不同的编解码器实现可以无缝替换。这种设计使得添加新的编解码器变得相对简单,也使得应用程序可以使用相同的API处理不同的编解码器。
核心数据结构:
// 编解码器上下文,包含编解码器的状态和参数
typedef struct AVCodecContext {
const AVClass *av_class; // AVClass类,用于日志和选项
const AVCodec *codec; // 编解码器
enum AVMediaType codec_type; // 编解码器类型(视频、音频等)
enum AVCodecID codec_id; // 编解码器ID
void *priv_data; // 编解码器私有数据
struct AVFrame *coded_frame; // 编码后的帧(已弃用)
int bit_rate; // 目标比特率
int width, height; // 视频的宽度和高度
int sample_rate, channels; // 音频的采样率和声道数
enum AVPixelFormat pix_fmt; // 视频像素格式
enum AVSampleFormat sample_fmt; // 音频样本格式
int gop_size; // GOP大小
int max_b_frames; // 最大B帧数
AVRational time_base; // 时间基准
// ... 其他字段
} AVCodecContext;
// 编解码器,描述一个编解码器的属性和功能
typedef struct AVCodec {
const char *name; // 编解码器名称
const char *long_name; // 编解码器长名称
enum AVMediaType type; // 编解码器类型
enum AVCodecID id; // 编解码器ID
int capabilities; // 编解码器能力
const AVRational *supported_framerates; // 支持的帧率列表
const enum AVPixelFormat *pix_fmts; // 支持的像素格式列表
const enum AVSampleFormat *sample_fmts; // 支持的样本格式列表
const int *supported_samplerates; // 支持的采样率列表
const uint64_t *channel_layouts; // 支持的声道布局列表
int (*init)(AVCodecContext *); // 初始化函数
int (*encode2)(AVCodecContext *, AVPacket *, const AVFrame *, int *); // 编码函数
int (*decode)(AVCodecContext *, AVFrame *, int *, const AVPacket *); // 解码函数
int (*close)(AVCodecContext *); // 关闭函数
// ... 其他字段
} AVCodec;
// 帧,表示原始的音频或视频数据
typedef struct AVFrame {
uint8_t **data; // 数据指针数组
int linesize[AV_NUM_DATA_POINTERS]; // 每个数据行的字节数
uint8_t **extended_data; // 扩展数据指针(用于多声道音频)
int width, height; // 视频的宽度和高度
int nb_samples; // 音频的样本数
int format; // 帧格式(像素格式或样本格式)
int64_t pts; // 显示时间戳
int64_t pkt_dts; // 数据包的解码时间戳
int sample_rate; // 音频的采样率
uint64_t channel_layout; // 音频的声道布局
AVDictionary *metadata; // 元数据
// ... 其他字段
} AVFrame;
这些结构体构成了libavcodec的核心API。通过它们,应用程序可以初始化编解码器,设置参数,进行编码或解码操作。
解码流程
视频解码是一个复杂的过程,涉及多个步骤和状态管理。让我们详细探讨libavcodec的解码流程:
解码流程的基本步骤如下:
- 查找解码器:使用
avcodec_find_decoder()函数根据编解码器ID(如AV_CODEC_ID_H264)查找对应的解码器。 - 创建解码器上下文:使用
avcodec_alloc_context3()函数创建一个AVCodecContext结构,用于存储解码器的状态和参数。 - 设置解码参数:根据输入流的特性(如分辨率、像素格式等)设置解码器上下文的参数。这些参数通常可以从
AVStream的codecpar字段获取。 - 打开解码器:使用
avcodec_open2()函数初始化解码器。这一步会分配解码器所需的资源,如参考帧缓冲区、线程上下文等。如果启用了硬件加速,还会初始化相应的硬件资源。 - 发送数据包:使用
avcodec_send_packet()函数将编码后的数据包发送给解码器。解码器会将数据包存储在内部缓冲区中,等待解码。 - 接收解码帧:使用
avcodec_receive_frame()函数从解码器获取解码后的帧。由于解码过程可能涉及帧重排序(特别是对于包含B帧的视频流),发送一个数据包可能不会立即产生一个解码帧,或者可能产生多个解码帧。 - 释放资源:解码完成后,使用
avcodec_free_context()函数释放解码器资源。
这种发送/接收的API设计(称为"send/receive API")是libavcodec的现代接口,相比旧的"decode API"更加灵活和高效。它允许解码器内部维护数据包和帧的缓冲区,更好地处理输入和输出之间的不匹配。
编码流程
视频编码与解码类似,但流程更为复杂,因为编码器需要做出更多的决策(如帧类型选择、运动估计、量化参数选择等):
编码流程的基本步骤如下:
- 查找编码器:使用
avcodec_find_encoder()函数根据编解码器ID查找对应的编码器。 - 创建编码器上下文:使用
avcodec_alloc_context3()函数创建一个AVCodecContext结构。 - 设置编码参数:设置编码器的各种参数,如比特率、分辨率、帧率、GOP大小、最大B帧数等。这些参数直接影响编码效率和质量。
- 打开编码器:使用
avcodec_open2()函数初始化编码器。 - 发送帧:使用
avcodec_send_frame()函数将原始帧发送给编码器。编码器会根据帧类型(I帧、P帧、B帧)和编码策略进行编码。 - 接收数据包:使用
avcodec_receive_packet()函数从编码器获取编码后的数据包。由于编码器可能需要多个帧才能生成一个数据包(特别是在使用B帧时),发送一个帧可能不会立即产生一个数据包。 - 刷新编码器:所有帧发送完成后,发送一个NULL帧给编码器,以刷新其内部缓冲区,并获取剩余的编码数据。
- 释放资源:编码完成后,使用
avcodec_free_context()函数释放编码器资源。
硬件加速
现代CPU通常包含专门的多媒体处理指令集(如x86的MMX、SSE、AVX,ARM的NEON等),而许多设备还配备了专用的视频处理硬件(如Intel的Quick Sync Video,NVIDIA的NVDEC/NVENC,AMD的VCN,移动设备的MediaCodec等)。libavcodec通过硬件加速API充分利用这些硬件资源,大幅提高编解码性能。
libavcodec支持多种硬件加速API:
- VA-API(Video Acceleration API):主要用于Linux系统,支持Intel和AMD的GPU。
- VDPAU(Video Decode and Presentation API for Unix):主要用于NVIDIA GPU在Linux系统上的硬件加速。
- DXVA2(DirectX Video Acceleration 2):用于Windows系统,支持各种GPU。
- D3D11VA:Windows系统上的另一种硬件加速API,基于Direct3D 11。
- VideoToolbox:用于macOS和iOS系统,利用Apple的硬件加速功能。
- MediaCodec:用于Android系统,利用设备的硬件编解码器。
- CUDA:利用NVIDIA GPU的通用计算能力进行视频处理。
- OpenCL:跨平台的通用计算框架,可用于视频处理。
使用硬件加速的基本步骤如下:
- 创建硬件设备上下文:使用
av_hwdevice_ctx_create()函数创建硬件设备上下文。 - 设置硬件加速参数:在编码器或解码器上下文中设置硬件加速相关的参数,如硬件设备类型、硬件帧格式等。
- 分配硬件帧:使用
av_hwframe_get_buffer()函数分配硬件帧缓冲区。 - 传输数据:在软件和硬件之间传输数据(如果需要)。
- 执行编解码:使用与软件编解码相同的API进行编解码操作,但数据存储在硬件内存中。
硬件加速虽然可以大幅提高性能,但也带来了一些复杂性:
- 兼容性问题:不同的硬件和驱动程序可能支持不同的功能和格式。
- 数据传输开销:在软件和硬件之间传输数据可能带来额外的开销。
- 功能限制:硬件加速可能不支持某些高级功能或特定的编码参数。
线程模型
多媒体处理,特别是视频编解码,是计算密集型任务。为了充分利用现代多核CPU的性能,libavcodec实现了复杂的线程模型。libavcodec支持以下几种线程模式:
- 切片级并行(Slice-level parallelism):将视频帧划分为多个切片(slice),每个线程处理一个切片。这种模式适用于大多数视频编解码器,但效率受限于切片数量。
- 帧级并行(Frame-level parallelism):多个线程并行处理多个帧。这种模式适用于解码,因为解码帧之间的依赖关系较少。对于编码,由于帧之间的依赖关系(如运动估计),实现起来更为复杂。
- 基于任务的并行(Task-based parallelism):将编解码过程分解为多个任务(如运动估计、DCT变换、量化等),由线程池动态分配任务。这种模式更为灵活,但实现复杂度也更高。
- 基于帧的线程+切片级并行(Frame-threading + slice-threading):结合帧级和切片级并行,实现更高程度的并行化。
libavcodec的线程模型通过 AVCodecContext的 thread_type和 thread_count参数控制。thread_type指定线程类型(如FF_THREAD_FRAME表示帧级线程,FF_THREAD_SLICE表示切片级线程),thread_count指定线程数量(0表示自动选择)。
线程编解码虽然可以提高性能,但也带来了一些挑战:
- 线程安全:确保编解码器在多线程环境下的正确性。
- 负载均衡:均匀分配工作负载,避免某些线程空闲而其他线程过载。
- 同步开销:最小化线程间的同步开销,避免性能下降。
- 内存访问模式:优化内存访问模式,减少缓存未命中。
滤镜与后处理
除了基本的编解码功能,libavcodec还提供了多种滤镜和后处理功能,用于改善视频质量或实现特殊效果:
- 去块效应滤波器(Deblocking filter):减少压缩引入的块效应,特别是在低比特率下。
- 去振铃滤波器(Deringing filter):减少压缩引入的振铃效应,提高边缘清晰度。
- 噪声抑制(Noise reduction):减少视频中的噪声,提高压缩效率。
- 锐化(Sharpening):增强视频的细节和边缘。
- 色彩校正(Color correction):调整视频的亮度、对比度、饱和度等。
这些滤镜可以在编解码过程中应用,也可以作为独立的处理步骤。libavcodec的滤镜功能与libavfilter库紧密集成,提供了丰富的视频处理能力。
libavfilter:多媒体处理的瑞士军刀
如果说libavcodec是FFmpeg的心脏,那么libavfilter(通常简称为lavfi)就是其多功能的工具箱。这个库提供了丰富的音频和视频滤镜,允许用户对原始的音频和视频数据进行各种处理,从简单的缩放、裁剪到复杂的计算机视觉算法。libavfilter的设计理念是提供一个灵活、高效的滤镜框架,使得各种处理操作可以无缝地组合在一起,形成复杂的处理链。
滤镜图(Filtergraph)概念
libavfilter的核心概念是"滤镜图"(Filtergraph),它描述了滤镜之间的连接关系。一个滤镜图由多个滤镜(Filter)和连接(Link)组成,每个滤镜有一个或多个输入和输出,连接则将滤镜的输出与另一个滤镜的输入相连。
滤镜图可以分为两种类型:
-
简单滤镜图:线性结构,一个滤镜的输出直接连接到下一个滤镜的输入。例如:
input -> scale -> overlay -> output -
复杂滤镜图:非线性结构,包含分支、合并等复杂连接。例如:
input1 -> split -> scale1 -> overlay -> output \-> scale2 -/ input2 -----------------/
滤镜图的概念使得libavfilter非常灵活,可以构建几乎任何复杂度的处理流程。
核心数据结构
libavfilter定义了几个关键的数据结构,用于表示滤镜和滤镜图:
// 滤镜上下文,表示一个滤镜实例
typedef struct AVFilterContext {
const AVClass *av_class; // AVClass类,用于日志和选项
const AVFilter *filter; // 滤镜描述
char *name; // 滤镜实例名称
AVFilterPad *input_pads; // 输入pad数组
AVFilterLink **inputs; // 输入链接数组
unsigned int nb_inputs; // 输入数量
AVFilterPad *output_pads; // 输出pad数组
AVFilterLink **outputs; // 输出链接数组
unsigned int nb_outputs; // 输出数量
void *priv; // 滤镜私有数据
// ... 其他字段
} AVFilterContext;
// 滤镜链接,表示两个滤镜之间的连接
typedef struct AVFilterLink {
AVFilterContext *src; // 源滤镜
AVFilterPad *srcpad; // 源pad
AVFilterContext *dst; // 目标滤镜
AVFilterPad *dstpad; // 目标pad
enum AVMediaType type; // 链接类型(视频、音频)
int w, h; // 视频的宽度和高度
AVRational sample_aspect_ratio; // 视频的像素宽高比
uint64_t channel_layout; // 音频的声道布局
int sample_rate; // 音频的采样率
enum AVFormat format; // 数据格式(像素格式或样本格式)
AVRational time_base; // 时间基准
// ... 其他字段
} AVFilterLink;
// 滤镜图,表示整个滤镜处理流程
typedef struct AVFilterGraph {
const AVClass *av_class; // AVClass类,用于日志和选项
AVFilterContext **filters; // 滤镜数组
unsigned int nb_filters; // 滤镜数量
char *scale_sws_opts; // swscale选项
char *resample_lavr_opts; // libavresample选项
void *thread_type; // 线程类型
int nb_threads; // 线程数量
// ... 其他字段
} AVFilterGraph;
这些结构体构成了libavfilter的核心API。通过它们,应用程序可以创建滤镜图,添加滤镜,连接滤镜,并处理数据。
滤镜类型与分类
libavfilter提供了数百种滤镜,可以根据功能分为以下几类:
视频滤镜:
- 基本变换:如
scale(缩放)、overlay(叠加)、crop(裁剪)、pad(填充)、rotate(旋转)、flip(翻转)等。 - 色彩处理:如
hue(色相调整)、saturation(饱和度调整)、brightness(亮度调整)、contrast(对比度调整)、colorbalance(色彩平衡)、colorchannelmixer(色彩通道混合)等。 - 降噪与增强:如
denoise(降噪)、sharpen(锐化)、unsharp(模糊)、edgedetect(边缘检测)、nlmeans(非局部均值降噪)等。 - 艺术效果:如
boxblur(盒状模糊)、convolution(卷积)、lut(查找表)、geq(几何方程)、vibrance(自然饱和度)等。 - 文本与图形:如
drawtext(绘制文本)、drawbox(绘制矩形)、drawgrid(绘制网格)、drawcircle(绘制圆形)等。 - 分析与调试:如
histogram(直方图)、waveform(波形图)、vectorscope(矢量示波器)、showinfo(显示帧信息)等。
音频滤镜:
- 基本处理:如
volume(音量调整)、pan(声像调整)、channelsplit(声道分离)、channelmap(声道映射)等。 - 均衡与滤波:如
equalizer(均衡器)、highpass(高通滤波)、lowpass(低通滤波)、bandpass(带通滤波)、bandreject(带阻滤波)等。 - 动态处理:如
compand(压缩/扩展)、gate(噪声门)、limiter(限制器)等。 - 混响与延迟:如
echo(回声)、reverb(混响)、adelay(音频延迟)等。 - 分析与调试:如
showwaves(显示波形)、ebur128(响度测量)、astats(音频统计)等。
多媒体滤镜:
- 音视频同步:如
asetpts(设置音频时间戳)、setpts(设置视频时间戳)、aresample(音频重采样)等。 - 流处理:如
split(分流)、concat(连接)、amix(音频混合)等。
滤镜图构建与执行
构建和执行滤镜图是libavfilter的核心功能。让我们详细探讨这个过程:
滤镜图构建和执行的基本步骤如下:
- 创建滤镜图:使用
avfilter_graph_alloc()函数创建一个空的滤镜图。 - 创建滤镜:使用
avfilter_graph_create_filter()函数创建滤镜实例。这个函数需要指定滤镜类型(如"scale"、"overlay"等)和实例名称。 - 连接滤镜:使用
avfilter_link()函数将滤镜的输出与另一个滤镜的输入连接起来。连接时会检查兼容性,如数据类型、格式、分辨率等。 - 配置滤镜图:使用
avfilter_graph_config()函数配置滤镜图。这一步会初始化所有滤镜,验证连接,并分配必要的资源。 - 处理数据:使用
av_buffersrc_add_frame()函数将输入帧添加到滤镜图的源滤镜(如buffer或abuffer),然后使用av_buffersink_get_frame()函数从滤镜图的汇滤镜(如buffersink或abuffersink)获取处理后的帧。 - 释放资源:处理完成后,使用
avfilter_graph_free()函数释放滤镜图和所有滤镜的资源。
滤镜描述语法
libavfilter提供了一种强大的文本语法,用于描述滤镜图。这种语法使得用户可以通过简单的文本字符串构建复杂的处理流程,而无需编写复杂的代码。
简单滤镜图语法:
简单滤镜图使用逗号分隔的滤镜列表,表示线性处理流程:
input_filter=filter1=option1=value1:option2=value2,filter2=option3=value3,output_filter
例如,将视频缩放到640x480并添加文本水印:
scale=640:480,drawtext=text='Hello World':x=10:y=10
复杂滤镜图语法:
复杂滤镜图使用分号分隔的滤镜链,方括号标记的流标签,以及复杂的连接关系:
[input_label]filter1=option1=value1[output_label1];[output_label1]filter2=option2=value2[output_label2]
例如,将两个视频流并排显示:
[left]scale=iw/2:ih[left_scaled];[right]scale=iw/2:ih[right_scaled];[left_scaled][right_scaled]hstack[output]
在这个例子中:
[left]和[right]是输入标签,表示两个输入视频流。scale=iw/2:ih将每个视频流的宽度减半,高度保持不变。[left_scaled]和[right_scaled]是中间标签,表示缩放后的视频流。hstack将两个视频流水平堆叠。[output]是输出标签,表示最终的视频流。
这种语法虽然看起来复杂,但非常强大,可以描述几乎任何复杂度的处理流程。
滤镜开发与扩展
libavfilter的一个强大特性是其可扩展性。开发者可以轻松地添加新的滤镜,扩展FFmpeg的功能。开发一个新滤镜通常包括以下步骤:
- 定义滤镜结构:创建一个结构体,存储滤镜的私有数据和状态。
- 实现滤镜回调函数:实现一组回调函数,如初始化、查询格式、处理帧、关闭等。
- 定义滤镜描述:创建一个
AVFilter结构,描述滤镜的属性,如输入/输出数量、支持的格式、选项等。 - 注册滤镜:在滤镜列表中注册新滤镜,使其可以被滤镜图使用。
以下是一个简单的视频反转滤镜的示例代码:
// 滤镜私有数据
typedef struct InvertContext {
int invert; // 是否反转
} InvertContext;
// 初始化回调
static int init(AVFilterContext *ctx)
{
InvertContext *s = ctx->priv;
s->invert = 1; // 默认反转
return 0;
}
// 查询格式回调
static int query_formats(AVFilterContext *ctx)
{
static const enum AVPixelFormat pix_fmts[] = {
AV_PIX_FMT_YUV420P, AV_PIX_FMT_YUV422P, AV_PIX_FMT_YUV444P,
AV_PIX_FMT_NONE
};
return ff_set_common_formats(ctx, ff_make_format_list(pix_fmts));
}
// 处理帧回调
static int filter_frame(AVFilterLink *inlink, AVFrame *in)
{
AVFilterContext *ctx = inlink->dst;
InvertContext *s = ctx->priv;
AVFilterLink *outlink = ctx->outputs[0];
AVFrame *out;
int i, j;
// 创建输出帧
out = ff_get_video_buffer(outlink, outlink->w, outlink->h);
if (!out) {
av_frame_free(&in);
return AVERROR(ENOMEM);
}
av_frame_copy_props(out, in);
// 反转像素值
for (i = 0; i < out->height; i++) {
for (j = 0; j < out->width; j++) {
out->data[0][i * out->linesize[0] + j] = 255 - in->data[0][i * in->linesize[0] + j];
}
}
// 复制色度通道(不反转)
for (i = 0; i < out->height / 2; i++) {
memcpy(out->data[1] + i * out->linesize[1],
in->data[1] + i * in->linesize[1], out->width / 2);
memcpy(out->data[2] + i * out->linesize[2],
in->data[2] + i * in->linesize[2], out->width / 2);
}
av_frame_free(&in);
return ff_filter_frame(outlink, out);
}
// 滤镜选项
static const AVOption invert_options[] = {
{ "invert", "invert the video", offsetof(InvertContext, invert), AV_OPT_TYPE_BOOL, { .i64 = 1 }, 0, 1, AV_OPT_FLAG_VIDEO_PARAM | AV_OPT_FLAG_FILTERING_PARAM },
{ NULL }
};
// 滤镜描述
static const AVFilterPad invert_inputs[] = {
{
.name = "default",
.type = AVMEDIA_TYPE_VIDEO,
.filter_frame = filter_frame,
},
{ NULL }
};
static const AVFilterPad invert_outputs[] = {
{
.name = "default",
.type = AVMEDIA_TYPE_VIDEO,
},
{ NULL }
};
AVFilter ff_vf_invert = {
.name = "invert",
.description = NULL_IF_CONFIG_SMALL("Invert the video."),
.priv_size = sizeof(InvertContext),
.init = init,
.query_formats = query_formats,
.inputs = invert_inputs,
.outputs = invert_outputs,
.priv_class = &invert_class,
.flags = AVFILTER_FLAG_SUPPORT_TIMELINE_GENERIC,
};
这个示例展示了如何创建一个简单的视频反转滤镜。实际开发中,滤镜可能需要处理更复杂的逻辑,如多线程、硬件加速、动态参数调整等。
性能优化
滤镜处理,特别是视频滤镜,通常是计算密集型任务。libavfilter采用了多种技术来优化性能:
- 多线程处理:libavfilter支持多线程滤镜处理,可以充分利用多核CPU的性能。每个滤镜可以指定其线程模型,如切片级并行、帧级并行等。
- SIMD优化:对于关键算法,libavfilter提供了针对不同CPU架构的手工汇编优化代码。这些优化代码利用了特定CPU的SIMD指令集(如MMX、SSE、AVX、NEON等),可以显著提高处理速度。
- 硬件加速:libavfilter支持利用GPU、专用媒体处理器等硬件加速滤镜处理。通过OpenCL、CUDA等技术,可以将计算密集型任务卸载到硬件。
- 内存管理优化:libavfilter采用引用计数的内存管理机制,减少数据拷贝。例如,当滤镜不需要修改输入数据时,可以直接传递引用,而不是创建副本。
- 延迟处理:某些滤镜(如降噪、稳定化)需要查看多个帧才能处理当前帧。libavfilter支持帧缓冲和延迟处理,确保滤镜可以访问必要的历史帧。
- 批处理:对于某些滤镜,一次处理多个帧比逐帧处理更高效。libavfilter支持批处理模式,减少函数调用开销。
这些优化技术使得libavfilter能够高效地处理高分辨率视频和复杂音频流,满足实时处理的需求。
FFmpeg的命令行工具
ffmpeg:多媒体处理的瑞士军刀
FFmpeg的命令行工具 ffmpeg是整个项目中最知名、最强大的组件。它是一个通用的多媒体处理工具,能够解码、编码、转码、流处理、滤镜处理和播放几乎所有已知的多媒体格式。ffmpeg工具的强大之处在于其灵活性和功能丰富性,通过简单的命令行参数,用户可以完成从简单的格式转换到复杂的视频处理的各种任务。
基本命令结构
ffmpeg命令的基本结构如下:
ffmpeg [全局选项] {[输入文件选项] -i 输入文件} ... {[输出文件选项] 输出文件} ...
这个结构表明,一个 ffmpeg命令可以包含多个输入文件和多个输出文件,每个文件可以有自己的选项。全局选项应用于整个命令,而输入文件选项和输出文件选项分别应用于特定的输入和输出文件。
常用场景与示例
让我们通过一些常见的使用场景来探索 ffmpeg的强大功能:
1. 基本格式转换
最简单的 ffmpeg用法是将一个多媒体文件转换为另一种格式:
ffmpeg -i input.mp4 output.avi
这个命令将 input.mp4文件转换为AVI格式的 output.avi文件。在这个过程中,FFmpeg会自动选择适当的编解码器。
2. 指定编解码器
有时我们需要明确指定使用的编解码器:
ffmpeg -i input.mp4 -c:v libx264 -c:a aac output.mp4
这个命令使用H.264视频编码器和AAC音频编码器重新编码输入文件。-c:v选项指定视频编解码器,-c:a选项指定音频编解码器。
3. 控制视频质量
我们可以通过比特率、CRF(恒定质量因子)等参数控制输出质量:
ffmpeg -i input.mp4 -c:v libx264 -crf 23 -preset medium output.mp4
这个命令使用H.264编码器,CRF值为23(默认值,范围0-51,值越小质量越高),预设为 medium(平衡编码速度和质量)。
4. 调整视频分辨率
使用 -vf(视频滤镜)选项可以调整视频分辨率:
ffmpeg -i input.mp4 -vf "scale=1280:720" output.mp4
这个命令将视频分辨率调整为1280x720。scale滤镜会自动保持宽高比,如果只指定一个维度:
ffmpeg -i input.mp4 -vf "scale=1280:-1" output.mp4
这个命令将视频宽度调整为1280像素,高度自动计算以保持宽高比。
5. 提取音频
从视频文件中提取音频:
ffmpeg -i input.mp4 -vn -c:a copy output.aac
这个命令使用 -vn(无视频)选项禁用视频流,使用 -c:a copy选项直接复制音频流而不重新编码。
6. 提取视频
从视频文件中提取视频(无音频):
ffmpeg -i input.mp4 -an -c:v copy output.mp4
这个命令使用 -an(无音频)选项禁用音频流,使用 -c:v copy选项直接复制视频流而不重新编码。
7. 截取视频片段
截取视频的特定时间段:
ffmpeg -i input.mp4 -ss 00:01:30 -t 00:00:30 output.mp4
这个命令从输入视频的1分30秒开始,截取30秒的视频片段。-ss选项指定开始时间,-t选项指定持续时间。
8. 合并视频文件
合并多个视频文件:
ffmpeg -f concat -i filelist.txt -c copy output.mp4
其中 filelist.txt包含要合并的文件列表:
file 'input1.mp4'
file 'input2.mp4'
file 'input3.mp4'
这个命令使用 concat分离器合并文件,-c copy选项确保不重新编码,保持原始质量。
9. 添加水印
在视频上添加图片水印:
ffmpeg -i input.mp4 -i watermark.png -filter_complex "overlay=10:10" output.mp4
这个命令使用 overlay滤镜将 watermark.png图片放置在视频的(10,10)位置。
10. 视频旋转
旋转视频:
ffmpeg -i input.mp4 -vf "transpose=1" output.mp4
这个命令使用 transpose滤镜旋转视频。transpose=1表示顺时针旋转90度,其他值表示不同的旋转方式。
11. 调整音频音量
调整音频音量:
ffmpeg -i input.mp4 -af "volume=1.5" output.mp4
这个命令使用 volume滤镜将音频音量调整为原来的1.5倍。
12. 音频降噪
使用音频降噪滤镜:
ffmpeg -i input.mp4 -af "afftdn=nf=-25" output.mp4
这个命令使用 afftdn滤镜进行音频降噪,nf=-25指定降噪强度。
13. 视频稳定化
稳定化视频:
ffmpeg -i input.mp4 -vf "vidstabdetect=stepsize=6:shakiness=10:accuracy=15" -f null -
ffmpeg -i input.mp4 -vf "vidstabtransform=input=transforms.trf:smoothing=30:crop=black" output.mp4
这个命令分两步进行:第一步检测视频中的运动并生成变换文件,第二步应用变换以稳定视频。
14. 生成视频缩略图
从视频中提取缩略图:
ffmpeg -i input.mp4 -vf "thumbnail,scale=640:360" -frames:v 1 thumbnail.jpg
这个命令使用 thumbnail滤镜选择视频中的代表性帧,然后缩放到640x360分辨率,并保存为JPEG图片。
15. 录制屏幕
录制屏幕(Linux):
ffmpeg -f x11grab -s 1920x1080 -i :0.0 output.mp4
这个命令使用 x11grab输入设备录制整个屏幕(1920x1080分辨率)。
16. 推流到RTMP服务器
将视频推流到RTMP服务器:
ffmpeg -re -i input.mp4 -c copy -f flv rtmp://server/live/stream_key
这个命令使用 -re选项以原始帧率读取输入文件,-c copy选项直接复制流而不重新编码,-f flv选项指定FLV封装格式,最后是RTMP服务器的URL。
高级选项与技巧
除了基本用法,ffmpeg还提供了许多高级选项和技巧,用于更精细的控制:
1. 两遍编码
对于某些编解码器(如libx264),两遍编码可以获得更好的质量和比特率控制:
ffmpeg -i input.mp4 -c:v libx264 -b:v 2000k -pass 1 -f null /dev/null
ffmpeg -i input.mp4 -c:v libx264 -b:v 2000k -pass 2 output.mp4
第一遍分析视频并创建统计文件,第二遍使用这些统计信息进行更优化的编码。
2. 硬件加速编码
使用硬件加速编码:
ffmpeg -i input.mp4 -c:v h264_nvenc -b:v 2000k output.mp4
这个命令使用NVIDIA的硬件编码器(h264_nvenc)进行编码。其他硬件编码器包括 h264_qsv(Intel Quick Sync)、h264_videotoolbox(Apple VideoToolbox)等。
3. 映射流
精确控制输入和输出流之间的映射:
ffmpeg -i input1.mp4 -i input2.mp4 -map 0:v:0 -map 1:a:0 -c copy output.mp4
这个命令从第一个输入文件(input1.mp4)选择第一个视频流(0:v:0),从第二个输入文件(input2.mp4)选择第一个音频流(1:a:0),合并到输出文件。
4. 元数据处理
处理文件的元数据:
ffmpeg -i input.mp4 -metadata title="My Video" -metadata artist="John Doe" output.mp4
这个命令为输出文件添加标题和艺术家元数据。
5. 章节处理
添加或修改章节:
ffmpeg -i input.mp4 -f ffmetadata metadata.txt
# 编辑metadata.txt
ffmpeg -i input.mp4 -i metadata.txt -map_metadata 1 -c copy output.mp4
这个命令首先提取元数据到 metadata.txt文件,然后编辑该文件,最后将修改后的元数据重新应用到输出文件。
6. 字幕处理
处理字幕:
ffmpeg -i input.mp4 -i subtitle.srt -c:v copy -c:a copy -c:s srt -map 0 -map 1 output.mp4
这个命令将SRT字幕文件添加到输出文件中。
7. 多比特率流
生成多比特率流,用于自适应流媒体:
ffmpeg -i input.mp4 \
-c:v libx264 -b:v 5000k -maxrate 5000k -bufsize 10000k -s 1920x1080 \
-c:a aac -b:a 192k \
-c:v libx264 -b:v 3000k -maxrate 3000k -bufsize 6000k -s 1280x720 \
-c:a aac -b:a 128k \
-c:v libx264 -b:v 1500k -maxrate 1500k -bufsize 3000k -s 854x480 \
-c:a aac -b:a 96k \
-f hls -var_stream_map "v:0,a:0 v:1,a:1 v:2,a:2" \
-master_pl_name master.m3u8 \
-hls_time 10 -hls_list_size 6 -hls_segment_filename "%v_%03d.ts" \
"%v_%v.m3u8"
这个命令生成三种不同比特率的流,并创建HLS播放列表和主播放列表。
8. 实时滤镜处理
应用实时滤镜处理:
ffmpeg -i input.mp4 -vf "split=2[a][b];[a]scale=iw:ih[a];[b]scale=iw/2:ih/2[b];[a][b]overlay=main_w-overlay_w:main_h-overlay_h" output.mp4
这个命令使用复杂的滤镜图,将视频分为两路,一路保持原始大小,另一路缩小一半,然后将缩小后的视频叠加在原始视频的右下角。
9. 性能监控
监控编码性能:
ffmpeg -i input.mp4 -c:v libx264 -crf 23 -preset medium -stats output.mp4
这个命令使用 -stats选项显示编码过程中的实时统计信息,如帧率、比特率、编码速度等。
10. 限制处理速度
限制处理速度,用于实时模拟:
ffmpeg -re -i input.mp4 -c:v libx264 output.mp4
这个命令使用 -re选项以原始帧率读取输入文件,模拟实时处理。
ffprobe:多媒体分析工具
ffprobe是FFmpeg套件中的多媒体分析工具,用于检查和分析多媒体文件的内容。它提供了详细的文件信息,包括容器格式、流信息、编解码器参数、帧数据、包数据等。ffprobe是调试、验证和学习多媒体文件的强大工具。
基本用法
ffprobe的基本用法很简单:
ffprobe input.mp4
这个命令会显示 input.mp4文件的基本信息,包括容器格式、流信息、持续时间、比特率等。
详细分析选项
ffprobe提供了多种选项,用于获取更详细的信息:
1. 显示流信息
ffprobe -show_streams input.mp4
这个命令显示文件中每个流的详细信息,包括编解码器类型、分辨率、帧率、采样率等。
2. 显示格式信息
ffprobe -show_format input.mp4
这个命令显示容器格式的详细信息,包括格式名称、版本、元数据等。
3. 显示帧信息
ffprobe -show_frames input.mp4
这个命令显示每个帧的详细信息,包括帧类型、时间戳、大小、关键帧标志等。
4. 显示包信息
ffprobe -show_packets input.mp4
这个命令显示每个包的详细信息,包括包类型、时间戳、大小、位置等。
5. 显示章节信息
ffprobe -show_chapters input.mp4
这个命令显示文件中的章节信息,包括章节开始时间、结束时间、标题等。
输出格式控制
ffprobe支持多种输出格式,便于进一步处理:
1. JSON格式
ffprobe -print_format json -show_streams input.mp4
这个命令以JSON格式输出流信息,便于程序解析。
2. XML格式
ffprobe -print_format xml -show_format input.mp4
这个命令以XML格式输出格式信息。
3. CSV格式
ffprobe -print_format csv -show_frames input.mp4
这个命令以CSV格式输出帧信息,便于导入电子表格。
4. 平面格式
ffprobe -print_format flat -show_packets input.mp4
这个命令以平面格式输出包信息,每个字段一行。
选择性输出
ffprobe允许选择性地输出特定信息:
1. 选择特定流
ffprobe -select_streams v:0 -show_frames input.mp4
这个命令只显示第一个视频流的帧信息。
2. 选择特定字段
ffprobe -show_entries frame=pkt_pts_time,pkt_dts_time input.mp4
这个命令只显示帧的PTS和DTS时间戳。
3. 使用数据提取
ffprobe -show_entries frame=width,height -of csv=p=0 input.mp4
这个命令提取帧的宽度和高度,以纯CSV格式输出(无标题行)。
高级分析功能
ffprobe还提供了一些高级分析功能:
1. 比特率分析
ffprobe -show_frames -of compact=p=0:nk=1 -f lavfi "movie=input.mp4,showinfo" | grep "pkt_size="
这个命令分析每个帧的大小,用于比特率分析。
2. 颜色分析
ffprobe -show_frames -of compact=p=0:nk=1 -f lavfi "movie=input.mp4,signalstats" | grep "YMIN="
这个命令分析视频帧的亮度信息。
3. 音频分析
ffprobe -show_frames -of compact=p=0:nk=1 -f lavfi "amovie=input.mp4,astats" | grep "Mean:"
这个命令分析音频样本的平均值。
4. 章节提取
ffprobe -show_chapters -print_format json input.mp4 | jq ".chapters[] | {start: .start_time, end: .end_time, title: .tags.title}"
这个命令提取章节信息,并使用 jq工具格式化输出。
ffplay:简单的媒体播放器
ffplay是FFmpeg套件中的简单媒体播放器。虽然它的功能不如专业的媒体播放器(如VLC、MPV等)丰富,但它对于快速预览和测试多媒体文件非常有用,特别是在开发过程中。
基本用法
ffplay的基本用法很简单:
ffplay input.mp4
这个命令会播放 input.mp4文件,使用默认的音频和视频输出设备。
播放控制
ffplay支持基本的播放控制:
- 空格键:暂停/继续播放
- 左箭头/右箭头:后退/前进10秒
- 上箭头/下箭头:后退/前进1分钟
- Page Up/Page Down:后退/前进10分钟
- f:切换全屏
- s:切换帧步进模式
- w:切换音频显示模式
- ESC:退出
高级选项
ffplay提供了多种高级选项,用于控制播放行为:
1. 指定播放起始时间
ffplay -ss 00:01:30 input.mp4
这个命令从1分30秒开始播放。
2. 禁用音频或视频
ffplay -an input.mp4 # 禁用音频
ffplay -vn input.mp4 # 禁用视频
3. 强制使用特定编解码器
ffplay -c:v h264 input.mp4
这个命令强制使用H.264解码器解码视频。
4. 应用滤镜
ffplay -vf "eq=brightness=0.1:saturation=1.5" input.mp4
这个命令应用亮度/饱和度滤镜播放视频。
5. 显示统计信息
ffplay -stats input.mp4
这个命令在播放时显示统计信息,如帧率、比特率、丢帧数等。
6. 循环播放
ffplay -loop 10 input.mp4
这个命令循环播放视频10次。
7. 播放网络流
ffplay rtmp://example.com/live/stream
这个命令播放RTMP网络流。
8. 播放原始数据
ffplay -f rawvideo -pixel_format yuv420p -video_size 640x480 input.yuv
这个命令播放原始YUV视频数据。
开发与调试用途
ffplay在开发和调试过程中特别有用:
1. 测试滤镜效果
ffplay -vf "scale=iw/2:ih/2" input.mp4
这个命令实时测试缩放滤镜的效果。
2. 验证解码器
ffplay -c:v libx264 input.mp4
这个命令强制使用特定的解码器,可以验证解码器是否正常工作。
3. 分析性能
ffplay -stats -threads 1 input.mp4
这个命令在单线程模式下播放视频,并显示统计信息,有助于分析解码性能。
4. 测试硬件加速
ffplay -hwaccel cuda -c:v h264_cuvid input.mp4
这个命令使用CUDA硬件加速解码视频,可以测试硬件加速是否正常工作。
5. 检查同步问题
ffplay -vf "showinfo" input.mp4
这个命令在播放时显示帧信息,有助于检查音视频同步问题。
FFmpeg的编程接口
libav* 库的C API
虽然FFmpeg的命令行工具功能强大,但真正的威力在于其底层的C API。通过这些API,开发者可以将FFmpeg的功能集成到自己的应用程序中,实现高度定制化的多媒体处理。FFmpeg提供了多个库,每个库专注于特定的功能领域,通过统一的API协同工作。
初始化与清理
使用FFmpeg库之前,必须进行初始化:
#include <libavcodec/avcodec.h>
#include <libavformat/avformat.h>
#include <libavfilter/avfilter.h>
#include <libavdevice/avdevice.h>
#include <libswscale/swscale.h>
#include <libswresample/swresample.h>
int main() {
// 注册所有编解码器、格式和滤镜
av_register_all();
avformat_network_init();
avfilter_register_all();
// ... 应用程序代码 ...
return 0;
}
这些初始化函数注册了所有可用的编解码器、格式、滤镜和协议,使得FFmpeg可以处理各种多媒体文件。
基本解码流程
让我们通过一个完整的视频解码示例,了解FFmpeg API的使用:
#include <libavcodec/avcodec.h>
#include <libavformat/avformat.h>
#include <libswscale/swscale.h>
#include <stdio.h>
int main(int argc, char *argv[]) {
if (argc < 2) {
printf("Usage: %s <input_file>\n", argv[0]);
return -1;
}
// 初始化FFmpeg
av_register_all();
// 打开输入文件
AVFormatContext *format_ctx = NULL;
if (avformat_open_input(&format_ctx, argv[1], NULL, NULL) != 0) {
printf("Could not open input file\n");
return -1;
}
// 获取流信息
if (avformat_find_stream_info(format_ctx, NULL) < 0) {
printf("Could not find stream information\n");
avformat_close_input(&format_ctx);
return -1;
}
// 查找视频流
int video_stream_index = -1;
for (int i = 0; i < format_ctx->nb_streams; i++) {
if (format_ctx->streams[i]->codecpar->codec_type == AVMEDIA_TYPE_VIDEO) {
video_stream_index = i;
break;
}
}
if (video_stream_index == -1) {
printf("Could not find video stream\n");
avformat_close_input(&format_ctx);
return -1;
}
// 获取解码器参数
AVCodecParameters *codec_params = format_ctx->streams[video_stream_index]->codecpar;
// 查找解码器
AVCodec *codec = avcodec_find_decoder(codec_params->codec_id);
if (!codec) {
printf("Unsupported codec\n");
avformat_close_input(&format_ctx);
return -1;
}
// 创建解码器上下文
AVCodecContext *codec_ctx = avcodec_alloc_context3(codec);
if (!codec_ctx) {
printf("Could not allocate codec context\n");
avformat_close_input(&format_ctx);
return -1;
}
// 复制解码器参数到解码器上下文
if (avcodec_parameters_to_context(codec_ctx, codec_params) < 0) {
printf("Could not copy codec parameters\n");
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return -1;
}
// 打开解码器
if (avcodec_open2(codec_ctx, codec, NULL) < 0) {
printf("Could not open codec\n");
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return -1;
}
// 创建图像转换上下文
struct SwsContext *sws_ctx = sws_getContext(
codec_ctx->width, codec_ctx->height, codec_ctx->pix_fmt,
codec_ctx->width, codec_ctx->height, AV_PIX_FMT_YUV420P,
SWS_BILINEAR, NULL, NULL, NULL
);
if (!sws_ctx) {
printf("Could not create scaling context\n");
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return -1;
}
// 分配帧缓冲区
AVFrame *frame = av_frame_alloc();
AVFrame *yuv_frame = av_frame_alloc();
AVPacket *packet = av_packet_alloc();
if (!frame || !yuv_frame || !packet) {
printf("Could not allocate frame or packet\n");
if (frame) av_frame_free(&frame);
if (yuv_frame) av_frame_free(&yuv_frame);
if (packet) av_packet_free(&packet);
sws_freeContext(sws_ctx);
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return -1;
}
// 分配YUV帧缓冲区
int num_bytes = av_image_get_buffer_size(AV_PIX_FMT_YUV420P, codec_ctx->width, codec_ctx->height, 1);
uint8_t *yuv_buffer = (uint8_t *)av_malloc(num_bytes * sizeof(uint8_t));
av_image_fill_arrays(yuv_frame->data, yuv_frame->linesize, yuv_buffer,
AV_PIX_FMT_YUV420P, codec_ctx->width, codec_ctx->height, 1);
// 读取并解码帧
while (av_read_frame(format_ctx, packet) >= 0) {
if (packet->stream_index == video_stream_index) {
// 发送数据包到解码器
if (avcodec_send_packet(codec_ctx, packet) < 0) {
printf("Error sending packet to decoder\n");
break;
}
// 接收解码后的帧
while (avcodec_receive_frame(codec_ctx, frame) == 0) {
// 转换像素格式
sws_scale(sws_ctx, (const uint8_t * const *)frame->data, frame->linesize, 0,
codec_ctx->height, yuv_frame->data, yuv_frame->linesize);
// 在这里处理YUV帧(例如保存、显示等)
printf("Decoded frame: %dx%d, pts=%ld\n",
frame->width, frame->height, frame->pts);
}
}
av_packet_unref(packet);
}
// 刷新解码器缓冲区
avcodec_send_packet(codec_ctx, NULL);
while (avcodec_receive_frame(codec_ctx, frame) == 0) {
// 处理剩余的帧
sws_scale(sws_ctx, (const uint8_t * const *)frame->data, frame->linesize, 0,
codec_ctx->height, yuv_frame->data, yuv_frame->linesize);
printf("Flushed frame: %dx%d, pts=%ld\n",
frame->width, frame->height, frame->pts);
}
// 清理资源
av_free(yuv_buffer);
av_frame_free(&frame);
av_frame_free(&yuv_frame);
av_packet_free(&packet);
sws_freeContext(sws_ctx);
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return 0;
}
这个示例展示了完整的视频解码流程,包括打开文件、查找流、初始化解码器、解码帧和转换像素格式。虽然代码较长,但每个步骤都有清晰的注释,便于理解。
基本编码流程
编码流程与解码流程类似,但方向相反:
#include <libavcodec/avcodec.h>
#include <libavformat/avformat.h>
#include <libswscale/swscale.h>
#include <stdio.h>
int main(int argc, char *argv[]) {
if (argc < 3) {
printf("Usage: %s <input_yuv_file> <output_file>\n", argv[0]);
return -1;
}
// 初始化FFmpeg
av_register_all();
// 查找编码器
AVCodec *codec = avcodec_find_encoder(AV_CODEC_ID_H264);
if (!codec) {
printf("H.264 encoder not found\n");
return -1;
}
// 创建编码器上下文
AVCodecContext *codec_ctx = avcodec_alloc_context3(codec);
if (!codec_ctx) {
printf("Could not allocate codec context\n");
return -1;
}
// 设置编码参数
codec_ctx->width = 640;
codec_ctx->height = 480;
codec_ctx->time_base = (AVRational){1, 25};
codec_ctx->framerate = (AVRational){25, 1};
codec_ctx->pix_fmt = AV_PIX_FMT_YUV420P;
codec_ctx->gop_size = 10;
codec_ctx->max_b_frames = 1;
codec_ctx->bit_rate = 400000;
// 打开编码器
if (avcodec_open2(codec_ctx, codec, NULL) < 0) {
printf("Could not open codec\n");
avcodec_free_context(&codec_ctx);
return -1;
}
// 创建输出格式上下文
AVFormatContext *format_ctx = NULL;
avformat_alloc_output_context2(&format_ctx, NULL, NULL, argv[2]);
if (!format_ctx) {
printf("Could not create output context\n");
avcodec_free_context(&codec_ctx);
return -1;
}
// 添加视频流
AVStream *video_stream = avformat_new_stream(format_ctx, codec);
if (!video_stream) {
printf("Could not create stream\n");
avformat_free_context(format_ctx);
avcodec_free_context(&codec_ctx);
return -1;
}
// 复制编码器参数到流
if (avcodec_parameters_from_context(video_stream->codecpar, codec_ctx) < 0) {
printf("Could not copy codec parameters\n");
avformat_free_context(format_ctx);
avcodec_free_context(&codec_ctx);
return -1;
}
video_stream->time_base = codec_ctx->time_base;
// 打开输出文件
if (avio_open(&format_ctx->pb, argv[2], AVIO_FLAG_WRITE) < 0) {
printf("Could not open output file\n");
avformat_free_context(format_ctx);
avcodec_free_context(&codec_ctx);
return -1;
}
// 写入文件头
if (avformat_write_header(format_ctx, NULL) < 0) {
printf("Error writing header\n");
avio_closep(&format_ctx->pb);
avformat_free_context(format_ctx);
avcodec_free_context(&codec_ctx);
return -1;
}
// 分配帧和数据包
AVFrame *frame = av_frame_alloc();
AVPacket *packet = av_packet_alloc();
if (!frame || !packet) {
printf("Could not allocate frame or packet\n");
if (frame) av_frame_free(&frame);
if (packet) av_packet_free(&packet);
avio_closep(&format_ctx->pb);
avformat_free_context(format_ctx);
avcodec_free_context(&codec_ctx);
return -1;
}
// 设置帧参数
frame->format = codec_ctx->pix_fmt;
frame->width = codec_ctx->width;
frame->height = codec_ctx->height;
// 分配帧缓冲区
if (av_frame_get_buffer(frame, 0) < 0) {
printf("Could not allocate frame buffer\n");
av_frame_free(&frame);
av_packet_free(&packet);
avio_closep(&format_ctx->pb);
avformat_free_context(format_ctx);
avcodec_free_context(&codec_ctx);
return -1;
}
// 打开输入YUV文件
FILE *yuv_file = fopen(argv[1], "rb");
if (!yuv_file) {
printf("Could not open input YUV file\n");
av_frame_free(&frame);
av_packet_free(&packet);
avio_closep(&format_ctx->pb);
avformat_free_context(format_ctx);
avcodec_free_context(&codec_ctx);
return -1;
}
// 计算YUV帧大小
int y_size = codec_ctx->width * codec_ctx->height;
int uv_size = y_size / 4;
int frame_size = y_size + 2 * uv_size;
// 编码循环
int frame_count = 0;
while (fread(frame->data[0], 1, y_size, yuv_file) == y_size &&
fread(frame->data[1], 1, uv_size, yuv_file) == uv_size &&
fread(frame->data[2], 1, uv_size, yuv_file) == uv_size) {
frame->pts = frame_count++;
// 发送帧到编码器
if (avcodec_send_frame(codec_ctx, frame) < 0) {
printf("Error sending frame to encoder\n");
break;
}
// 接收编码后的数据包
while (avcodec_receive_packet(codec_ctx, packet) == 0) {
// 设置数据包时间戳
av_packet_rescale_ts(packet, codec_ctx->time_base, video_stream->time_base);
packet->stream_index = video_stream->index;
// 写入数据包
if (av_interleaved_write_frame(format_ctx, packet) < 0) {
printf("Error writing packet\n");
break;
}
}
}
// 刷新编码器缓冲区
avcodec_send_frame(codec_ctx, NULL);
while (avcodec_receive_packet(codec_ctx, packet) == 0) {
av_packet_rescale_ts(packet, codec_ctx->time_base, video_stream->time_base);
packet->stream_index = video_stream->index;
if (av_interleaved_write_frame(format_ctx, packet) < 0) {
printf("Error writing packet\n");
break;
}
}
// 写入文件尾
av_write_trailer(format_ctx);
// 清理资源
fclose(yuv_file);
av_frame_free(&frame);
av_packet_free(&packet);
avio_closep(&format_ctx->pb);
avformat_free_context(format_ctx);
avcodec_free_context(&codec_ctx);
return 0;
}
这个示例展示了完整的视频编码流程,包括初始化编码器、创建输出文件、读取YUV数据、编码帧和写入文件。与解码示例类似,每个步骤都有清晰的注释。
滤镜图编程
使用libavfilter API构建和处理滤镜图:
#include <libavcodec/avcodec.h>
#include <libavformat/avformat.h>
#include <libavfilter/avfilter.h>
#include <libavfilter/buffersink.h>
#include <libavfilter/buffersrc.h>
#include <libavutil/opt.h>
#include <stdio.h>
int main(int argc, char *argv[]) {
if (argc < 3) {
printf("Usage: %s <input_file> <output_file>\n", argv[0]);
return -1;
}
// 初始化FFmpeg
av_register_all();
avfilter_register_all();
// 打开输入文件
AVFormatContext *format_ctx = NULL;
if (avformat_open_input(&format_ctx, argv[1], NULL, NULL) != 0) {
printf("Could not open input file\n");
return -1;
}
// 获取流信息
if (avformat_find_stream_info(format_ctx, NULL) < 0) {
printf("Could not find stream information\n");
avformat_close_input(&format_ctx);
return -1;
}
// 查找视频流
int video_stream_index = -1;
for (int i = 0; i < format_ctx->nb_streams; i++) {
if (format_ctx->streams[i]->codecpar->codec_type == AVMEDIA_TYPE_VIDEO) {
video_stream_index = i;
break;
}
}
if (video_stream_index == -1) {
printf("Could not find video stream\n");
avformat_close_input(&format_ctx);
return -1;
}
// 获取解码器参数
AVCodecParameters *codec_params = format_ctx->streams[video_stream_index]->codecpar;
// 查找解码器
AVCodec *codec = avcodec_find_decoder(codec_params->codec_id);
if (!codec) {
printf("Unsupported codec\n");
avformat_close_input(&format_ctx);
return -1;
}
// 创建解码器上下文
AVCodecContext *codec_ctx = avcodec_alloc_context3(codec);
if (!codec_ctx) {
printf("Could not allocate codec context\n");
avformat_close_input(&format_ctx);
return -1;
}
// 复制解码器参数到解码器上下文
if (avcodec_parameters_to_context(codec_ctx, codec_params) < 0) {
printf("Could not copy codec parameters\n");
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return -1;
}
// 打开解码器
if (avcodec_open2(codec_ctx, codec, NULL) < 0) {
printf("Could not open codec\n");
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return -1;
}
// 创建滤镜图
AVFilterGraph *filter_graph = avfilter_graph_alloc();
if (!filter_graph) {
printf("Could not create filter graph\n");
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return -1;
}
// 创建源滤镜(buffer)
AVFilterContext *buffer_src_ctx = NULL;
const AVFilter *buffer_src = avfilter_get_by_name("buffer");
if (!buffer_src) {
printf("Could not find buffer source filter\n");
avfilter_graph_free(&filter_graph);
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return -1;
}
// 设置源滤镜参数
char args[512];
snprintf(args, sizeof(args),
"video_size=%dx%d:pix_fmt=%d:time_base=%d/%d:pixel_aspect=%d/%d",
codec_ctx->width, codec_ctx->height, codec_ctx->pix_fmt,
codec_ctx->time_base.num, codec_ctx->time_base.den,
codec_ctx->sample_aspect_ratio.num, codec_ctx->sample_aspect_ratio.den);
if (avfilter_graph_create_filter(&buffer_src_ctx, buffer_src, "in", args, NULL, filter_graph) < 0) {
printf("Could not create buffer source\n");
avfilter_graph_free(&filter_graph);
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return -1;
}
// 创建汇滤镜(buffersink)
AVFilterContext *buffer_sink_ctx = NULL;
const AVFilter *buffer_sink = avfilter_get_by_name("buffersink");
if (!buffer_sink) {
printf("Could not find buffer sink filter\n");
avfilter_graph_free(&filter_graph);
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return -1;
}
if (avfilter_graph_create_filter(&buffer_sink_ctx, buffer_sink, "out", NULL, NULL, filter_graph) < 0) {
printf("Could not create buffer sink\n");
avfilter_graph_free(&filter_graph);
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return -1;
}
// 设置汇滤镜参数
enum AVPixelFormat pix_fmts[] = { AV_PIX_FMT_YUV420P, AV_PIX_FMT_NONE };
if (av_opt_set_int_list(buffer_sink_ctx, "pix_fmts", pix_fmts, AV_PIX_FMT_NONE, AV_OPT_SEARCH_CHILDREN) < 0) {
printf("Could not set output pixel format\n");
avfilter_graph_free(&filter_graph);
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return -1;
}
// 创建缩放滤镜
AVFilterContext *scale_ctx = NULL;
const AVFilter *scale = avfilter_get_by_name("scale");
if (!scale) {
printf("Could not find scale filter\n");
avfilter_graph_free(&filter_graph);
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return -1;
}
if (avfilter_graph_create_filter(&scale_ctx, scale, "scale", "w=640:h=480", NULL, filter_graph) < 0) {
printf("Could not create scale filter\n");
avfilter_graph_free(&filter_graph);
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return -1;
}
// 连接滤镜
if (avfilter_link(buffer_src_ctx, 0, scale_ctx, 0) < 0 ||
avfilter_link(scale_ctx, 0, buffer_sink_ctx, 0) < 0) {
printf("Error connecting filters\n");
avfilter_graph_free(&filter_graph);
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return -1;
}
// 配置滤镜图
if (avfilter_graph_config(filter_graph, NULL) < 0) {
printf("Error configuring filter graph\n");
avfilter_graph_free(&filter_graph);
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return -1;
}
// 分配帧和数据包
AVFrame *frame = av_frame_alloc();
AVFrame *filtered_frame = av_frame_alloc();
AVPacket *packet = av_packet_alloc();
if (!frame || !filtered_frame || !packet) {
printf("Could not allocate frame or packet\n");
if (frame) av_frame_free(&frame);
if (filtered_frame) av_frame_free(&filtered_frame);
if (packet) av_packet_free(&packet);
avfilter_graph_free(&filter_graph);
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return -1;
}
// 读取并解码帧
while (av_read_frame(format_ctx, packet) >= 0) {
if (packet->stream_index == video_stream_index) {
// 发送数据包到解码器
if (avcodec_send_packet(codec_ctx, packet) < 0) {
printf("Error sending packet to decoder\n");
break;
}
// 接收解码后的帧
while (avcodec_receive_frame(codec_ctx, frame) == 0) {
// 将帧发送到滤镜图
if (av_buffersrc_add_frame(buffer_src_ctx, frame) < 0) {
printf("Error adding frame to filter graph\n");
break;
}
// 从滤镜图获取处理后的帧
while (av_buffersink_get_frame(buffer_sink_ctx, filtered_frame) >= 0) {
// 在这里处理过滤后的帧(例如保存、显示等)
printf("Filtered frame: %dx%d, pts=%ld\n",
filtered_frame->width, filtered_frame->height, filtered_frame->pts);
av_frame_unref(filtered_frame);
}
}
}
av_packet_unref(packet);
}
// 刷新解码器缓冲区
avcodec_send_packet(codec_ctx, NULL);
while (avcodec_receive_frame(codec_ctx, frame) == 0) {
// 将帧发送到滤镜图
if (av_buffersrc_add_frame(buffer_src_ctx, frame) < 0) {
printf("Error adding frame to filter graph\n");
break;
}
// 从滤镜图获取处理后的帧
while (av_buffersink_get_frame(buffer_sink_ctx, filtered_frame) >= 0) {
printf("Flushed filtered frame: %dx%d, pts=%ld\n",
filtered_frame->width, filtered_frame->height, filtered_frame->pts);
av_frame_unref(filtered_frame);
}
}
// 清理资源
av_frame_free(&frame);
av_frame_free(&filtered_frame);
av_packet_free(&packet);
avfilter_graph_free(&filter_graph);
avcodec_free_context(&codec_ctx);
avformat_close_input(&format_ctx);
return 0;
}
这个示例展示了如何使用libavfilter API构建和处理滤镜图。在这个例子中,我们创建了一个简单的滤镜图,包含一个源滤镜(buffer)、一个缩放滤镜(scale)和一个汇滤镜(buffersink)。解码后的帧被发送到滤镜图,经过缩放处理后,再从滤镜图中获取。
错误处理与日志
FFmpeg提供了强大的日志系统,帮助开发者调试问题:
#include <libavutil/log.h>
int main() {
// 设置日志级别
av_log_set_level(AV_LOG_DEBUG);
// 自定义日志回调函数
av_log_set_callback(custom_log_callback);
// ... 应用程序代码 ...
return 0;
}
void custom_log_callback(void *ptr, int level, const char *fmt, va_list vl) {
// 自定义日志处理
if (level <= av_log_get_level()) {
char log_line[1024];
vsnprintf(log_line, sizeof(log_line), fmt, vl);
printf("[CUSTOM LOG] %s", log_line);
}
}
FFmpeg的日志系统支持多个级别,从 AV_LOG_PANIC(最高级别)到 AV_LOG_DEBUG(最低级别)。开发者可以根据需要设置日志级别,或者提供自定义的日志回调函数。
内存管理
FFmpeg使用引用计数机制管理内存,开发者需要正确地释放资源:
// 分配帧
AVFrame *frame = av_frame_alloc();
if (!frame) {
// 处理错误
}
// 使用帧...
// 释放帧
av_frame_free(&frame);
// 分配数据包
AVPacket *packet = av_packet_alloc();
if (!packet) {
// 处理错误
}
// 使用数据包...
// 释放数据包
av_packet_free(&packet);
// 分配编解码器上下文
AVCodecContext *codec_ctx = avcodec_alloc_context3(codec);
if (!codec_ctx) {
// 处理错误
}
// 使用编解码器上下文...
// 释放编解码器上下文
avcodec_free_context(&codec_ctx);
// 打开格式上下文
AVFormatContext *format_ctx = NULL;
if (avformat_open_input(&format_ctx, filename, NULL, NULL) != 0) {
// 处理错误
}
// 使用格式上下文...
// 关闭格式上下文
avformat_close_input(&format_ctx);
FFmpeg的内存管理遵循一个简单的规则:每个分配函数(如 av_frame_alloc、av_packet_alloc等)都有一个对应的释放函数(如 av_frame_free、av_packet_free等)。开发者必须确保在不再需要资源时调用相应的释放函数,以避免内存泄漏。
高级编程技巧
掌握了基本的FFmpeg API后,我们可以探索一些更高级的编程技巧,这些技巧可以帮助我们构建更高效、更稳定的多媒体应用程序。
硬件加速编程
使用FFmpeg的硬件加速API可以大幅提高编解码性能:
#include <libavcodec/avcodec.h>
#include <libavutil/hwcontext.h>
int main() {
// 查找支持硬件加速的解码器
AVCodec *codec = avcodec_find_decoder_by_name("h264_cuvid");
if (!codec) {
printf("Hardware accelerated decoder not found\n");
return -1;
}
// 创建解码器上下文
AVCodecContext *codec_ctx = avcodec_alloc_context3(codec);
if (!codec_ctx) {
printf("Could not allocate codec context\n");
return -1;
}
// 创建硬件设备上下文
AVBufferRef *hw_device_ctx = NULL;
if (av_hwdevice_ctx_create(&hw_device_ctx, AV_HWDEVICE_TYPE_CUDA, NULL, NULL, 0) < 0) {
printf("Could not create hardware device context\n");
avcodec_free_context(&codec_ctx);
return -1;
}
// 设置硬件设备上下文
codec_ctx->hw_device_ctx = av_buffer_ref(hw_device_ctx);
// 打开解码器
if (avcodec_open2(codec_ctx, codec, NULL) < 0) {
printf("Could not open codec\n");
av_buffer_unref(&hw_device_ctx);
avcodec_free_context(&codec_ctx);
return -1;
}
// 分配硬件帧
AVFrame *hw_frame = av_frame_alloc();
AVFrame *sw_frame = av_frame_alloc();
if (!hw_frame || !sw_frame) {
printf("Could not allocate frames\n");
if (hw_frame) av_frame_free(&hw_frame);
if (sw_frame) av_frame_free(&sw_frame);
av_buffer_unref(&hw_device_ctx);
avcodec_free_context(&codec_ctx);
return -1;
}
// 解码循环
AVPacket *packet = av_packet_alloc();
if (!packet) {
printf("Could not allocate packet\n");
av_frame_free(&hw_frame);
av_frame_free(&sw_frame);
av_buffer_unref(&hw_device_ctx);
avcodec_free_context(&codec_ctx);
return -1;
}
while (/* 读取数据包 */) {
// 发送数据包到解码器
if (avcodec_send_packet(codec_ctx, packet) < 0) {
printf("Error sending packet to decoder\n");
break;
}
// 接收解码后的帧
while (avcodec_receive_frame(codec_ctx, hw_frame) == 0) {
// 将硬件帧复制到软件帧
if (av_hwframe_transfer_data(sw_frame, hw_frame, 0) < 0) {
printf("Error transferring frame from hardware to software\n");
av_frame_unref(hw_frame);
break;
}
// 处理软件帧...
av_frame_unref(hw_frame);
av_frame_unref(sw_frame);
}
av_packet_unref(packet);
}
// 清理资源
av_packet_free(&packet);
av_frame_free(&hw_frame);
av_frame_free(&sw_frame);
av_buffer_unref(&hw_device_ctx);
avcodec_free_context(&codec_ctx);
return 0;
}
这个示例展示了如何使用NVIDIA的CUDA硬件加速进行视频解码。关键步骤包括:
- 查找支持硬件加速的解码器(如"h264_cuvid")。
- 创建硬件设备上下文(使用
av_hwdevice_ctx_create)。 - 将硬件设备上下文设置到解码器上下文。
- 分配硬件帧和软件帧。
- 在解码循环中,将硬件帧复制到软件帧进行处理。
不同的硬件加速API(如VA-API、VDPAU、DXVA2等)有不同的实现细节,但基本流程类似。
多线程编程
FFmpeg支持多线程编解码和处理,可以充分利用现代多核CPU的性能:
#include <libavcodec/avcodec.h>
int main() {
// 创建解码器上下文
AVCodecContext *codec_ctx = avcodec_alloc_context3(codec);
if (!codec_ctx) {
printf("Could not allocate codec context\n");
return -1;
}
// 设置线程参数
codec_ctx->thread_type = FF_THREAD_FRAME | FF_THREAD_SLICE;
codec_ctx->thread_count = 0; // 0表示自动选择线程数
// 打开解码器
if (avcodec_open2(codec_ctx, codec, NULL) < 0) {
printf("Could not open codec\n");
avcodec_free_context(&codec_ctx);
return -1;
}
// 解码循环...
// 清理资源
avcodec_free_context(&codec_ctx);
return 0;
}
FFmpeg支持两种线程模式:
- 帧级线程(Frame-threading):多个线程并行处理多个帧。这种模式适用于解码,因为解码帧之间的依赖关系较少。
- 切片级线程(Slice-threading):将视频帧划分为多个切片,每个线程处理一个切片。这种模式适用于大多数视频编解码器。
开发者可以通过 thread_type参数选择线程模式,通过 thread_count参数指定线程数量(0表示自动选择)。
自定义IO
FFmpeg允许开发者提供自定义的IO函数,用于处理特殊的数据源(如网络流、内存缓冲区等):
#include <libavformat/avformat.h>
#include <libavformat/avio.h>
// 自定义IO上下文
typedef struct CustomIOContext {
uint8_t *buffer;
size_t buffer_size;
size_t buffer_pos;
} CustomIOContext;
// 自定义读取函数
static int custom_read(void *opaque, uint8_t *buf, int buf_size) {
CustomIOContext *ctx = (CustomIOContext *)opaque;
// 计算可读取的字节数
size_t remaining = ctx->buffer_size - ctx->buffer_pos;
size_t to_read = (remaining < buf_size) ? remaining : buf_size;
if (to_read == 0) {
return AVERROR_EOF; // 文件结束
}
// 复制数据
memcpy(buf, ctx->buffer + ctx->buffer_pos, to_read);
ctx->buffer_pos += to_read;
return to_read;
}
// 自定义写入函数
static int custom_write(void *opaque, uint8_t *buf, int buf_size) {
CustomIOContext *ctx = (CustomIOContext *)opaque;
// 检查缓冲区是否有足够空间
if (ctx->buffer_pos + buf_size > ctx->buffer_size) {
// 扩展缓冲区
size_t new_size = ctx->buffer_size * 2;
uint8_t *new_buffer = av_realloc(ctx->buffer, new_size);
if (!new_buffer) {
return AVERROR(ENOMEM);
}
ctx->buffer = new_buffer;
ctx->buffer_size = new_size;
}
// 复制数据
memcpy(ctx->buffer + ctx->buffer_pos, buf, buf_size);
ctx->buffer_pos += buf_size;
return buf_size;
}
// 自定义查找函数
static int64_t custom_seek(void *opaque, int64_t offset, int whence) {
CustomIOContext *ctx = (CustomIOContext *)opaque;
switch (whence) {
case SEEK_SET:
// 从文件开头偏移
if (offset < 0 || offset > ctx->buffer_size) {
return -1;
}
ctx->buffer_pos = offset;
break;
case SEEK_CUR:
// 从当前位置偏移
if (ctx->buffer_pos + offset < 0 || ctx->buffer_pos + offset > ctx->buffer_size) {
return -1;
}
ctx->buffer_pos += offset;
break;
case SEEK_END:
// 从文件末尾偏移
if (offset > 0 || ctx->buffer_size + offset < 0) {
return -1;
}
ctx->buffer_pos = ctx->buffer_size + offset;
break;
case AVSEEK_SIZE:
// 返回文件大小
return ctx->buffer_size;
default:
return -1;
}
return ctx->buffer_pos;
}
int main() {
// 创建自定义IO上下文
CustomIOContext *ctx = av_mallocz(sizeof(CustomIOContext));
if (!ctx) {
printf("Could not allocate custom IO context\n");
return -1;
}
// 初始化缓冲区
ctx->buffer_size = 1024 * 1024; // 1MB
ctx->buffer = av_malloc(ctx->buffer_size);
if (!ctx->buffer) {
printf("Could not allocate buffer\n");
av_free(ctx);
return -1;
}
// 填充缓冲区(这里应该是实际的数据)
// ...
// 创建IO上下文
AVIOContext *io_ctx = avio_alloc_context(
av_malloc(4096), // 内部缓冲区
4096, // 内部缓冲区大小
0, // 写入标志(0表示只读)
ctx, // 不透明数据
custom_read, // 读取函数
NULL, // 写入函数(NULL表示不支持写入)
custom_seek // 查找函数
);
if (!io_ctx) {
printf("Could not allocate IO context\n");
av_free(ctx->buffer);
av_free(ctx);
return -1;
}
// 创建格式上下文
AVFormatContext *format_ctx = avformat_alloc_context();
if (!format_ctx) {
printf("Could not allocate format context\n");
avio_context_free(&io_ctx);
av_free(ctx->buffer);
av_free(ctx);
return -1;
}
// 设置IO上下文
format_ctx->pb = io_ctx;
// 打开输入
if (avformat_open_input(&format_ctx, NULL, NULL, NULL) != 0) {
printf("Could not open input\n");
avformat_free_context(format_ctx);
avio_context_free(&io_ctx);
av_free(ctx->buffer);
av_free(ctx);
return -1;
}
// 获取流信息
if (avformat_find_stream_info(format_ctx, NULL) < 0) {
printf("Could not find stream information\n");
avformat_close_input(&format_ctx);
avio_context_free(&io_ctx);
av_free(ctx->buffer);
av_free(ctx);
return -1;
}
// 处理多媒体数据...
// 清理资源
avformat_close_input(&format_ctx);
avio_context_free(&io_ctx);
av_free(ctx->buffer);
av_free(ctx);
return 0;
}
这个示例展示了如何使用FFmpeg的自定义IO功能从内存缓冲区读取多媒体数据。关键步骤包括:
- 定义自定义IO上下文,包含缓冲区和位置信息。
- 实现自定义的读取、写入和查找函数。
- 创建AVIOContext,将自定义IO上下文和函数与之关联。
- 创建AVFormatContext,并将AVIOContext设置为其pb字段。
- 使用avformat_open_input打开输入,注意这里传递NULL作为文件名,因为我们使用自定义IO。
自定义IO功能使得FFmpeg可以处理各种特殊的数据源,如网络流、内存缓冲区、加密数据等。
自定义滤镜开发
除了使用FFmpeg提供的内置滤镜,开发者还可以开发自定义滤镜,扩展FFmpeg的功能:
#include <libavfilter/avfilter.h>
#include <libavutil/opt.h>
#include <libavutil/pixdesc.h>
// 滤镜私有数据
typedef struct CustomFilterContext {
const AVClass *class;
float strength; // 滤镜强度参数
} CustomFilterContext;
// 滤镜初始化函数
static av_cold int init(AVFilterContext *ctx)
{
CustomFilterContext *s = ctx->priv;
s->strength = 1.0f; // 默认强度
return 0;
}
// 滤镜查询格式函数
static int query_formats(AVFilterContext *ctx)
{
static const enum AVPixelFormat pix_fmts[] = {
AV_PIX_FMT_YUV420P, AV_PIX_FMT_YUV422P, AV_PIX_FMT_YUV444P,
AV_PIX_FMT_NONE
};
AVFilterFormats *fmts_list = ff_make_format_list(pix_fmts);
if (!fmts_list)
return AVERROR(ENOMEM);
return ff_set_common_formats(ctx, fmts_list);
}
// 滤镜配置输入输出函数
static int config_props(AVFilterLink *inlink)
{
AVFilterContext *ctx = inlink->dst;
CustomFilterContext *s = ctx->priv;
// 检查输入参数
if (s->strength < 0.0f || s->strength > 10.0f) {
av_log(ctx, AV_LOG_ERROR, "Invalid strength value: %f\n", s->strength);
return AVERROR(EINVAL);
}
return 0;
}
// 滤镜处理帧函数
static int filter_frame(AVFilterLink *inlink, AVFrame *in)
{
AVFilterContext *ctx = inlink->dst;
CustomFilterContext *s = ctx->priv;
AVFilterLink *outlink = ctx->outputs[0];
AVFrame *out;
int i, j;
// 创建输出帧
out = ff_get_video_buffer(outlink, outlink->w, outlink->h);
if (!out) {
av_frame_free(&in);
return AVERROR(ENOMEM);
}
av_frame_copy_props(out, in);
// 应用滤镜效果(这里是一个简单的示例:调整亮度)
for (i = 0; i < out->height; i++) {
for (j = 0; j < out->width; j++) {
// 调整Y分量(亮度)
int y = in->data[0][i * in->linesize[0] + j];
y = av_clip_uint8(y + (int)(s->strength * 10)); // 调整亮度
out->data[0][i * out->linesize[0] + j] = y;
}
}
// 复制色度分量(不修改)
for (i = 0; i < out->height / 2; i++) {
memcpy(out->data[1] + i * out->linesize[1],
in->data[1] + i * in->linesize[1], out->width / 2);
memcpy(out->data[2] + i * out->linesize[2],
in->data[2] + i * in->linesize[2], out->width / 2);
}
av_frame_free(&in);
return ff_filter_frame(outlink, out);
}
// 滤镜选项定义
static const AVOption custom_filter_options[] = {
{ "strength", "set filter strength", offsetof(CustomFilterContext, strength), AV_OPT_TYPE_FLOAT, { .dbl = 1.0 }, 0.0, 10.0, AV_OPT_FLAG_VIDEO_PARAM | AV_OPT_FLAG_FILTERING_PARAM },
{ NULL }
};
// 滤镜类定义
static const AVClass custom_filter_class = {
.class_name = "custom_filter",
.item_name = av_default_item_name,
.option = custom_filter_options,
.version = LIBAVUTIL_VERSION_INT,
};
// 滤镜输入pad定义
static const AVFilterPad custom_filter_inputs[] = {
{
.name = "default",
.type = AVMEDIA_TYPE_VIDEO,
.config_props = config_props,
.filter_frame = filter_frame,
},
{ NULL }
};
// 滤镜输出pad定义
static const AVFilterPad custom_filter_outputs[] = {
{
.name = "default",
.type = AVMEDIA_TYPE_VIDEO,
},
{ NULL }
};
// 滤镜定义
AVFilter ff_vf_custom_filter = {
.name = "custom_filter",
.description = NULL_IF_CONFIG_SMALL("Custom filter example"),
.priv_size = sizeof(CustomFilterContext),
.priv_class = &custom_filter_class,
.init = init,
.query_formats = query_formats,
.inputs = custom_filter_inputs,
.outputs = custom_filter_outputs,
.flags = AVFILTER_FLAG_SUPPORT_TIMELINE_GENERIC,
};
这个示例展示了如何开发一个简单的自定义视频滤镜。关键步骤包括:
- 定义滤镜私有数据结构,包含滤镜的参数和状态。
- 实现滤镜的回调函数,如初始化、查询格式、配置输入输出、处理帧等。
- 定义滤镜的选项,允许用户通过参数控制滤镜行为。
- 定义滤镜的输入和输出pad,描述滤镜的接口。
- 定义滤镜本身,将所有组件组合在一起。
开发自定义滤镜需要深入理解FFmpeg的滤镜框架和视频处理原理,但它提供了极大的灵活性,允许开发者实现几乎任何视频处理算法。
FFmpeg的性能优化
编解码性能优化
FFmpeg的性能优化是一个复杂而重要的主题,特别是在处理高分辨率视频或实时流媒体时。编解码是多媒体处理中最计算密集型的部分,因此是优化的重点。
编解码器选择与配置
选择合适的编解码器和参数配置是性能优化的第一步:
// 选择快速编码预设
AVCodecContext *codec_ctx = ...;
av_opt_set(codec_ctx->priv_data, "preset", "ultrafast", 0);
// 调整编码参数以优化速度
codec_ctx->rc_lookahead = 0; // 禁用前瞻
codec_ctx->mbtree = 0; // 禁用宏块树
codec_ctx->mixed_refs = 0; // 禁用混合参考帧
codec_ctx->8x8dct = 0; // 禁用8x8 DCT
codec_ctx->coder_type = 0; // 使用CAVLC而不是CABAC
codec_ctx->me_cmp = 0; // 使用简单的SAD作为运动估计比较函数
codec_ctx->me_subpel_quality = 0; // 降低子像素运动估计质量
codec_ctx->refs = 1; // 使用最少的参考帧
codec_ctx->gop_size = 0; // 禁用GOP(仅I帧)
这些参数调整会降低编码质量,但会显著提高编码速度。在实际应用中,需要在速度和质量之间找到平衡。
线程优化
充分利用多核CPU是提高编解码性能的关键:
// 设置线程参数
AVCodecContext *codec_ctx = ...;
codec_ctx->thread_type = FF_THREAD_FRAME | FF_THREAD_SLICE;
codec_ctx->thread_count = 0; // 0表示自动选择线程数
// 对于编码器,可以设置切片数量
av_opt_set_int(codec_ctx->priv_data, "slices", 4, 0);
FFmpeg支持两种线程模式:
- 帧级线程:多个线程并行处理多个帧。这种模式适用于解码,因为解码帧之间的依赖关系较少。
- 切片级线程:将视频帧划分为多个切片,每个线程处理一个切片。这种模式适用于大多数视频编解码器。
对于编码器,还可以通过设置切片数量来提高并行度。更多的切片意味着更好的并行性,但可能会降低压缩效率。
硬件加速
利用GPU或专用媒体处理器进行硬件加速是提高编解码性能的最有效方法:
// 使用NVIDIA NVDEC/NVENC硬件加速
AVCodec *decoder = avcodec_find_decoder_by_name("h264_cuvid");
AVCodec *encoder = avcodec_find_encoder_by_name("h264_nvenc");
// 使用Intel Quick Sync硬件加速
AVCodec *decoder = avcodec_find_decoder_by_name("h264_qsv");
AVCodec *encoder = avcodec_find_encoder_by_name("h264_qsv");
// 使用AMD AMF硬件加速
AVCodec *decoder = avcodec_find_decoder_by_name("h264_amf");
AVCodec *encoder = avcodec_find_encoder_by_name("h264_amf");
// 使用Apple VideoToolbox硬件加速
AVCodec *decoder = avcodec_find_decoder_by_name("h264_videotoolbox");
AVCodec *encoder = avcodec_find_encoder_by_name("h264_videotoolbox");
硬件加速可以大幅提高编解码性能,特别是在处理高分辨率视频时。然而,硬件加速也有一些限制:
- 兼容性:不同的硬件和驱动程序可能支持不同的功能和格式。
- 质量:硬件加速的编码质量可能不如软件编码器。
- 灵活性:硬件加速可能不支持某些高级编码参数或功能。
SIMD优化
FFmpeg使用SIMD(单指令多数据)指令集优化关键算法,充分利用现代CPU的并行计算能力:
// 检查CPU支持的SIMD指令集
int cpu_flags = av_get_cpu_flags();
if (cpu_flags & AV_CPU_FLAG_SSE2) {
printf("CPU supports SSE2\n");
}
if (cpu_flags & AV_CPU_FLAG_AVX2) {
printf("CPU supports AVX2\n");
}
if (cpu_flags & AV_CPU_FLAG_NEON) {
printf("CPU supports NEON\n");
}
// 强制使用特定的SIMD指令集
av_set_cpu_flags(AV_CPU_FLAG_SSE2);
FFmpeg自动检测CPU支持的SIMD指令集,并使用相应的优化代码。开发者也可以强制使用特定的指令集,这在某些调试场景中可能有用。
零拷贝优化
减少数据拷贝是提高性能的重要策略:
// 使用引用计数帧
AVFrame *frame = av_frame_alloc();
frame->buf[0] = av_buffer_alloc(frame_size);
frame->data[0] = frame->buf[0]->data;
frame->linesize[0] = frame_width;
// 传递帧引用,而不是拷贝数据
AVFrame *ref_frame = av_frame_clone(frame);
// 使用ref_frame...
av_frame_free(&ref_frame);
av_frame_free(&frame);
FFmpeg的引用计数机制允许在不拷贝数据的情况下共享帧数据。这在处理高分辨率视频时特别有用,可以显著减少内存带宽消耗。
滤镜性能优化
滤镜处理是另一个性能关键点,特别是在使用复杂滤镜链时:
滤镜图优化
优化滤镜图的结构和参数可以显著提高性能:
// 使用简单的滤镜链
const char *filter_desc = "scale=1280:720,format=yuv420p";
// 避免不必要的格式转换
const char *filter_desc = "scale=1280:720:flags=fast_bilinear";
// 使用多线程滤镜处理
AVFilterGraph *graph = avfilter_graph_alloc();
av_opt_set(graph->priv_data, "threads", "4", 0);
优化滤镜图的一些策略包括:
- 简化滤镜链:移除不必要的滤镜,合并功能相似的滤镜。
- 减少格式转换:尽量保持一致的像素格式,避免不必要的格式转换。
- 使用多线程:启用滤镜图的多线程处理,充分利用多核CPU。
滤镜参数优化
调整滤镜参数可以在质量和性能之间找到平衡:
// 使用快速缩放算法
const char *filter_desc = "scale=1280:720:flags=fast_bilinear";
// 降低去噪强度
const char *filter_desc = "hqdn3d=luma_spatial=4:chroma_spatial=2";
// 使用简单的锐化算法
const char *filter_desc = "unsharp=5:5:1.0:5:5:0.0";
不同的滤镜参数对性能的影响很大。在实际应用中,需要根据具体需求调整参数,在质量和性能之间找到平衡。
硬件加速滤镜
某些滤镜支持硬件加速,可以大幅提高处理速度:
// 使用OpenCL加速的滤镜
const char *filter_desc = "scale_opencl=1280:720";
// 使用CUDA加速的滤镜
const char *filter_desc = "scale_cuda=1280:720";
// 使用Vulkan加速的滤镜
const char *filter_desc = "scale_vulkan=1280:720";
硬件加速滤镜利用GPU的并行计算能力,特别适合计算密集型的滤镜操作,如缩放、色彩转换、去噪等。
I/O性能优化
I/O操作是多媒体处理中的另一个性能瓶颈,特别是在处理网络流或大文件时:
缓冲区优化
调整缓冲区大小可以显著提高I/O性能:
// 设置输入缓冲区大小
AVFormatContext *format_ctx = ...;
format_ctx->pb->buffer_size = 4 * 1024 * 1024; // 4MB
// 设置输出缓冲区大小
AVIOContext *output_ctx = ...;
output_ctx->buffer_size = 4 * 1024 * 1024; // 4MB
较大的缓冲区可以减少系统调用的次数,提高I/O效率。然而,过大的缓冲区可能会增加内存使用和延迟。
零拷贝I/O
使用零拷贝技术可以减少数据在内核空间和用户空间之间的拷贝:
// 使用mmap进行文件I/O
int fd = open(filename, O_RDONLY);
void *mapped_data = mmap(NULL, file_size, PROT_READ, MAP_PRIVATE, fd, 0);
// 创建AVBufferRef引用映射的数据
AVBufferRef *buf_ref = av_buffer_create(mapped_data, file_size, NULL, NULL, 0);
// 使用buf_ref创建数据包
AVPacket *pkt = av_packet_alloc();
pkt->buf = buf_ref;
pkt->data = mapped_data;
pkt->size = file_size;
// 处理数据包...
av_packet_free(&pkt);
av_buffer_unref(&buf_ref);
munmap(mapped_data, file_size);
close(fd);
零拷贝I/O特别适合处理大文件,可以显著减少CPU使用率和内存带宽消耗。
异步I/O
使用异步I/O可以提高I/O密集型应用的性能:
// 使用libaio进行异步文件I/O
#include <libaio.h>
io_context_t io_ctx;
struct iocb cb;
struct iocb *cbs[1];
struct io_event events[1];
// 初始化异步I/O上下文
io_setup(1, &io_ctx);
// 准备异步读取操作
io_prep_pread(&cb, fd, buffer, buffer_size, offset);
cbs[0] = &cb;
// 提交异步读取操作
io_submit(io_ctx, 1, cbs);
// 等待I/O完成
io_getevents(io_ctx, 1, 1, events, NULL);
// 处理读取的数据...
// 清理资源
io_destroy(io_ctx);
异步I/O允许应用程序在等待I/O操作完成时执行其他任务,提高整体吞吐量。这在处理多个输入流或网络流时特别有用。
内存管理优化
高效的内存管理是多媒体应用性能的关键:
内存池
使用内存池可以减少内存分配和释放的开销:
// 创建帧池
AVFramePool *frame_pool = av_frame_pool_alloc(
AV_PIX_FMT_YUV420P, // 像素格式
1920, // 宽度
1080, // 高度
32, // 对齐
10 // 池大小
);
if (!frame_pool) {
// 处理错误
}
// 从池中获取帧
AVFrame *frame = av_frame_pool_get(frame_pool);
if (!frame) {
// 处理错误
}
// 使用帧...
// 将帧返回池中
av_frame_pool_put(frame_pool, frame);
// 销毁帧池
av_frame_pool_free(&frame_pool);
内存池特别适合处理固定大小的对象,如视频帧。它可以减少内存碎片,提高分配和释放的速度。
内存对齐
确保内存对齐可以提高SIMD操作的效率:
// 分配对齐的内存
void *aligned_mem = av_malloc(size + AV_INPUT_BUFFER_PADDING_SIZE);
// 检查对齐
if (((uintptr_t)aligned_mem & 15) == 0) {
printf("Memory is 16-byte aligned\n");
}
// 使用对齐的内存...
// 释放内存
av_free(aligned_mem);
现代CPU的SIMD指令通常要求数据对齐到特定的边界(如16字节或32字节)。确保内存对齐可以显著提高SIMD操作的性能。
内存映射文件
对于大文件,使用内存映射可以提高访问效率:
// 映射文件到内存
int fd = open(filename, O_RDONLY);
off_t file_size = lseek(fd, 0, SEEK_END);
lseek(fd, 0, SEEK_SET);
void *mapped_data = mmap(NULL, file_size, PROT_READ, MAP_PRIVATE, fd, 0);
if (mapped_data == MAP_FAILED) {
// 处理错误
}
// 使用映射的数据...
// 解除映射
munmap(mapped_data, file_size);
close(fd);
内存映射文件允许操作系统按需加载数据,减少内存使用,并利用操作系统的页面缓存提高访问速度。
FFmpeg的安全考虑
输入验证与安全处理
FFmpeg作为一个多媒体处理工具,经常需要处理来自不可信来源的输入文件。这些文件可能包含恶意构造的数据,导致缓冲区溢出、拒绝服务或其他安全问题。因此,输入验证和安全处理是使用FFmpeg时必须考虑的重要方面。
输入文件验证
在处理输入文件之前,应该进行基本的验证:
// 检查文件大小
struct stat st;
if (stat(filename, &st) == 0) {
if (st.st_size > MAX_FILE_SIZE) {
printf("File too large\n");
return -1;
}
}
// 检查文件扩展名
const char *ext = strrchr(filename, '.');
if (ext) {
if (strcasecmp(ext, ".mp4") != 0 &&
strcasecmp(ext, ".avi") != 0 &&
strcasecmp(ext, ".mkv") != 0) {
printf("Unsupported file extension\n");
return -1;
}
}
这些基本的检查可以防止处理明显异常的文件,但它们不足以防止所有安全问题。
安全打开文件
使用FFmpeg的安全打开文件功能:
// 使用安全模式打开文件
AVFormatContext *format_ctx = NULL;
AVDictionary *options = NULL;
av_dict_set(&options, "safe", "1", 0);
av_dict_set(&options, "protocol_whitelist", "file,http,https,tcp,tls", 0);
if (avformat_open_input(&format_ctx, filename, NULL, &options) != 0) {
printf("Could not open input file\n");
av_dict_free(&options);
return -1;
}
av_dict_free(&options);
这些选项可以限制FFmpeg使用的协议,防止处理潜在危险的协议(如gopher、rtp等)。
限制资源使用
限制FFmpeg的资源使用可以防止拒绝服务攻击:
// 限制最大帧数
format_ctx->max_frame_count = 10000;
// 限制最大分析时间
format_ctx->max_analyze_duration = 5 * AV_TIME_BASE;
// 限制最大帧大小
AVCodecContext *codec_ctx = ...;
codec_ctx->max_pixels = 1920 * 1080; // 限制最大分辨率
这些限制可以防止处理异常大的文件或帧,避免消耗过多的系统资源。
错误处理
正确处理错误可以防止程序崩溃或进入不稳定状态:
// 检查所有FFmpeg函数的返回值
if (avformat_open_input(&format_ctx, filename, NULL, NULL) != 0) {
printf("Could not open input file\n");
return -1;
}
// 检查解码错误
int ret = avcodec_send_packet(codec_ctx, packet);
if (ret < 0) {
if (ret == AVERROR(EAGAIN)) {
// 需要更多输入
} else if (ret == AVERROR_EOF) {
// 解码器已刷新
} else {
// 其他错误
char err_buf[AV_ERROR_MAX_STRING_SIZE];
av_strerror(ret, err_buf, sizeof(err_buf));
printf("Decoder error: %s\n", err_buf);
}
}
正确的错误处理可以使应用程序更加健壮,能够优雅地处理各种异常情况。
沙箱与隔离
对于处理不可信输入的应用程序,沙箱和隔离是重要的安全措施:
进程隔离
将FFmpeg处理放在单独的进程中:
// 创建子进程处理FFmpeg
pid_t pid = fork();
if (pid == 0) {
// 子进程
// 设置资源限制
struct rlimit rl;
rl.rlim_cur = rl.rlim_max = 100 * 1024 * 1024; // 100MB内存限制
setrlimit(RLIMIT_AS, &rl);
// 执行FFmpeg处理
execl("/usr/bin/ffmpeg", "ffmpeg", "-i", input_file, output_file, NULL);
exit(1);
} else if (pid > 0) {
// 父进程
int status;
waitpid(pid, &status, 0);
if (WIFEXITED(status) && WEXITSTATUS(status) == 0) {
printf("FFmpeg processing completed successfully\n");
} else {
printf("FFmpeg processing failed\n");
}
} else {
// fork失败
printf("Could not create child process\n");
return -1;
}
进程隔离可以防止FFmpeg中的漏洞影响主应用程序,即使FFmpeg被攻击,攻击者也只能获得子进程的权限。
容器化
使用容器技术(如Docker)隔离FFmpeg处理:
# Dockerfile
FROM ubuntu:20.04
RUN apt-get update && apt-get install -y ffmpeg
USER nobody
CMD ["ffmpeg"]
# 运行FFmpeg容器
docker run --rm \
--memory=100m \
--cpus=1 \
--read-only \
--tmpfs /tmp:rw,size=100m \
-v $(pwd)/input:/input:ro \
-v $(pwd)/output:/output:rw \
ffmpeg \
-i /input/input.mp4 \
/output/output.mp4
容器化提供了更强的隔离性,可以限制FFmpeg的资源使用(CPU、内存、磁盘等),并限制其对文件系统的访问。
seccomp过滤器
使用seccomp过滤器限制FFmpeg的系统调用:
#include <seccomp.h>
#include <sys/prctl.h>
// 设置seccomp过滤器
void setup_seccomp() {
scmp_filter_ctx ctx = seccomp_init(SCMP_ACT_KILL);
if (!ctx) {
perror("seccomp_init");
exit(1);
}
// 允许必要的系统调用
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(read), 0);
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(write), 0);
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(open), 0);
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(close), 0);
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(mmap), 0);
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(munmap), 0);
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(brk), 0);
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(exit), 0);
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(exit_group), 0);
// 加载过滤器
if (seccomp_load(ctx) < 0) {
perror("seccomp_load");
seccomp_release(ctx);
exit(1);
}
seccomp_release(ctx);
}
int main() {
// 启用no_new_privs
if (prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0) < 0) {
perror("prctl");
return -1;
}
// 设置seccomp过滤器
setup_seccomp();
// 运行FFmpeg处理...
return 0;
}
seccomp过滤器可以限制FFmpeg只能调用特定的系统调用,减少攻击面。即使攻击者能够利用FFmpeg中的漏洞执行任意代码,seccomp过滤器也会阻止其执行危险的系统调用。
安全编码实践
在使用FFmpeg API时,遵循安全编码实践可以减少安全漏洞:
缓冲区安全
确保所有缓冲区操作都是安全的:
// 安全的字符串复制
char dest[100];
snprintf(dest, sizeof(dest), "%s", source);
// 安全的内存分配
size_t size = width * height * 3 / 2; // YUV420P格式
uint8_t *buffer = (uint8_t *)av_malloc(size + AV_INPUT_BUFFER_PADDING_SIZE);
if (!buffer) {
// 处理错误
}
FFmpeg提供了 AV_INPUT_BUFFER_PADDING_SIZE常量,建议在分配缓冲区时添加额外的填充空间,以防止某些编解码器读取缓冲区末尾之外的数据。
整数安全
防止整数溢出和其他整数安全问题:
// 安全的整数乘法
size_t size;
if (av_mul_size(width, height, &size) < 0) {
printf("Integer overflow\n");
return -1;
}
// 安全的整数加法
int total;
if (av_add_int(a, b, &total) < 0) {
printf("Integer overflow\n");
return -1;
}
FFmpeg提供了一些辅助函数,用于安全地进行整数运算,防止溢出。
内存管理
正确管理内存,防止内存泄漏和悬空指针:
// 使用RAII模式管理资源
typedef struct FFmpegContext {
AVFormatContext *format_ctx;
AVCodecContext *codec_ctx;
AVFrame *frame;
AVPacket *packet;
} FFmpegContext;
// 初始化上下文
int init_ffmpeg_context(FFmpegContext *ctx, const char *filename) {
memset(ctx, 0, sizeof(FFmpegContext));
// 打开输入文件
if (avformat_open_input(&ctx->format_ctx, filename, NULL, NULL) != 0) {
cleanup_ffmpeg_context(ctx);
return -1;
}
// ... 其他初始化 ...
return 0;
}
// 清理上下文
void cleanup_ffmpeg_context(FFmpegContext *ctx) {
if (ctx->packet) av_packet_free(&ctx->packet);
if (ctx->frame) av_frame_free(&ctx->frame);
if (ctx->codec_ctx) avcodec_free_context(&ctx->codec_ctx);
if (ctx->format_ctx) avformat_close_input(&ctx->format_ctx);
memset(ctx, 0, sizeof(FFmpegContext));
}
// 使用上下文
int process_file(const char *filename) {
FFmpegContext ctx;
if (init_ffmpeg_context(&ctx, filename) < 0) {
return -1;
}
// 处理文件...
cleanup_ffmpeg_context(&ctx);
return 0;
}
使用RAII(资源获取即初始化)模式可以确保资源在不再需要时被正确释放,即使在发生错误时也是如此。
FFmpeg的未来发展
新兴编解码器支持
多媒体领域不断发展,新的编解码器不断涌现。FFmpeg作为多媒体处理的核心工具,必须紧跟这些发展,支持新的编解码器和技术。
AV1编解码器
AV1(AOMedia Video 1)是一个开放、免版税的视频编解码器,由开放媒体联盟(AOMedia)开发。它旨在提供比现有的编解码器(如H.264和HEVC)更高的压缩效率,同时保持免版税的优势。
// 使用AV1编码器
AVCodec *encoder = avcodec_find_encoder_by_name("libaom-av1");
if (!encoder) {
printf("AV1 encoder not found\n");
return -1;
}
AVCodecContext *codec_ctx = avcodec_alloc_context3(encoder);
if (!codec_ctx) {
printf("Could not allocate codec context\n");
return -1;
}
// 设置AV1编码参数
codec_ctx->profile = FF_PROFILE_AV1_MAIN;
codec_ctx->level = 0; // 自动选择级别
codec_ctx->gop_size = 30;
codec_ctx->max_b_frames = 0; // AV1不支持B帧
codec_ctx->pix_fmt = AV_PIX_FMT_YUV420P;
codec_ctx->bit_rate = 2000000; // 2Mbps
// 设置AV1特定选项
av_opt_set(codec_ctx->priv_data, "cpu-used", "4", 0); // 编码速度/质量权衡
av_opt_set(codec_ctx->priv_data, "row-mt", "1", 0); // 启用行级多线程
av_opt_set(codec_ctx->priv_data, "tile-rows", "2", 0); // 设置切片行数
av_opt_set(codec_ctx->priv_data, "tile-columns", "2", 0); // 设置切片列数
AV1的主要优势包括:
- 更高的压缩效率:在相同质量下,AV1比H.264节省约50%的比特率,比HEVC节省约20%的比特率。
- 免版税:与HEVC不同,AV1完全免版税,没有任何专利费用。
- 开放标准:AV1是一个开放标准,由多个行业领导者共同开发。
然而,AV1的编码复杂度较高,需要更多的计算资源。FFmpeg通过优化和多线程支持,努力降低AV1编码的资源需求。
VVC编解码器
VVC(Versatile Video Coding,也称为H.266)是MPEG开发的最新视频编解码器标准。它旨在提供比HEVC更高的压缩效率,特别是在高分辨率视频(如4K和8K)方面。
// 使用VVC编码器
AVCodec *encoder = avcodec_find_encoder_by_name("libvvenc");
if (!encoder) {
printf("VVC encoder not found\n");
return -1;
}
AVCodecContext *codec_ctx = avcodec_alloc_context3(encoder);
if (!codec_ctx) {
printf("Could not allocate codec context\n");
return -1;
}
// 设置VVC编码参数
codec_ctx->profile = FF_PROFILE_VVC_MAIN_10;
codec_ctx->level = 0; // 自动选择级别
codec_ctx->gop_size = 32;
codec_ctx->max_b_frames = 7; // VVC支持更多B帧
codec_ctx->pix_fmt = AV_PIX_FMT_YUV420P10; // 10位色深
codec_ctx->bit_rate = 1500000; // 1.5Mbps
// 设置VVC特定选项
av_opt_set(codec_ctx->priv_data, "preset", "medium", 0); // 编码预设
av_opt_set(codec_ctx->priv_data, "tune", "psnr", 0); // 优化目标
av_opt_set(codec_ctx->priv_data, "ctu", "64", 0); // CTU大小
VVC的主要创新包括:
- 更灵活的块划分:VVC引入了更灵活的编码树单元(CTU)划分方式,可以更好地适应视频内容。
- 多类型树(MTT):VVC使用多类型树结构,可以更高效地表示视频内容。
- 自适应环路滤波(ALF):VVC引入了新的环路滤波技术,可以进一步提高压缩效率。
- 屏幕内容编码工具:VVC包含专门针对屏幕内容(如计算机生成的文本和图形)的编码工具。
VVC的压缩效率比HEVC提高了约40-50%,但编码复杂度也相应增加。FFmpeg正在积极优化VVC编码器,以提高其实用性。
LCEVC编解码器
LCEVC(Low Complexity Enhancement Video Coding)是一种独特的视频编解码器,它将基础层和增强层分离,允许使用现有的编解码器(如H.264或HEVC)作为基础层,然后添加一个轻量级的增强层来提高质量。
// 使用LCEVC编码器
AVCodec *encoder = avcodec_find_encoder_by_name("liblcevc");
if (!encoder) {
printf("LCEVC encoder not found\n");
return -1;
}
AVCodecContext *codec_ctx = avcodec_alloc_context3(encoder);
if (!codec_ctx) {
printf("Could not allocate codec context\n");
return -1;
}
// 设置LCEVC编码参数
codec_ctx->profile = FF_PROFILE_LCEVC_MAIN;
codec_ctx->pix_fmt = AV_PIX_FMT_YUV420P;
codec_ctx->bit_rate = 1000000; // 1Mbps
// 设置LCEVC特定选项
av_opt_set(codec_ctx->priv_data, "base_codec", "h264", 0); // 基础编解码器
av_opt_set(codec_ctx->priv_data, "base_profile", "high", 0); // 基础编解码器配置
av_opt_set(codec_ctx->priv_data, "base_level", "4.1", 0); // 基础编解码器级别
av_opt_set(codec_ctx->priv_data, "enhancement_strength", "medium", 0); // 增强层强度
LCEVC的主要优势包括:
- 低复杂度:LCEVC的增强层计算复杂度低,适合在资源受限的设备上使用。
- 向后兼容:LCEVC可以与现有的编解码器和播放器兼容,只需要添加一个轻量级的增强层解码器。
- **渐进式
质量提升**:LCEVC允许基础层和增强层分别传输,实现渐进式质量提升,适应不同的网络条件。
LCEVC的这种分层设计使其特别适合流媒体应用,可以在不增加太多复杂度的情况下显著提高视频质量。FFmpeg对LCEVC的支持正在不断发展,预计将在未来的版本中提供更完整的实现。
机器学习与AI集成
近年来,机器学习和人工智能技术在多媒体处理领域取得了显著进展。FFmpeg也开始探索将这些技术集成到其框架中,以提供更智能、更高效的多媒体处理能力。
超分辨率
超分辨率技术使用机器学习模型将低分辨率视频转换为高分辨率视频,是AI在视频处理中最成功的应用之一。
// 使用基于AI的超分辨率滤镜
const char *filter_desc = "sr=dnn_model=model.pb:scale_factor=2";
// 创建滤镜图
AVFilterGraph *graph = avfilter_graph_alloc();
if (!graph) {
printf("Could not create filter graph\n");
return -1;
}
// 解析滤镜描述
AVFilterInOut *inputs = NULL;
AVFilterInOut *outputs = NULL;
if (avfilter_graph_parse2(graph, filter_desc, &inputs, &outputs) < 0) {
printf("Could not parse filter graph\n");
avfilter_graph_free(&graph);
return -1;
}
// 配置滤镜图
if (avfilter_graph_config(graph, NULL) < 0) {
printf("Could not configure filter graph\n");
avfilter_inout_free(&inputs);
avfilter_inout_free(&outputs);
avfilter_graph_free(&graph);
return -1;
}
// 使用滤镜图处理视频...
FFmpeg的 sr滤镜支持多种深度学习模型,如ESPCN、FSRCNN、LapSRN等。这些模型可以显著提高视频的分辨率,同时保持或甚至提高视觉质量。
视频去噪与增强
AI技术也可以用于视频去噪和增强,提供比传统算法更好的效果:
// 使用基于AI的去噪滤镜
const char *filter_desc = "derain=dnn_model=model.pb";
// 使用基于AI的视频增强滤镜
const char *filter_desc = "dnn_processing=dnn_model=model.pb:input=yuv420p:output=yuv420p";
// 使用基于AI的色彩增强滤镜
const char *filter_desc = "colorize=dnn_model=model.pb";
这些AI滤镜可以处理各种视频质量问题,如雨滴、低光照、色彩失真等。它们通过学习大量视频数据,能够理解视频内容并做出智能的增强决策。
视频插帧
视频插帧技术使用AI模型在现有帧之间生成新的帧,提高视频的帧率,使运动更加流畅:
// 使用基于AI的视频插帧滤镜
const char *filter_desc = "minterpolate=fps=60:mi_mode=mci:me_mode=bidir:mc_mode=aobmc:me=epzs:vsbmc=1:scd=fdiff";
// 使用基于深度学习的视频插帧滤镜
const char *filter_desc = "dnn_interpolate=dnn_model=model.pb:fps=60";
视频插帧技术特别适合将低帧率视频(如24fps的电影)转换为高帧率视频(如60fps),提供更流畅的观看体验。
对象检测与跟踪
AI技术还可以用于视频中的对象检测和跟踪,为视频分析和编辑提供强大的工具:
// 使用基于AI的对象检测滤镜
const char *filter_desc = "dnn_detect=dnn_model=model.pb:labels=labels.txt:confidence=0.5";
// 使用基于AI的对象跟踪滤镜
const char *filter_desc = "dnn_tracking=dnn_model=model.pb:labels=labels.txt:confidence=0.5";
这些滤镜可以检测和跟踪视频中的特定对象(如人脸、车辆、动物等),为视频内容分析、自动编辑、隐私保护等应用提供基础。
实时流媒体与低延迟处理
随着直播、视频会议和云游戏等实时应用的普及,低延迟视频处理变得越来越重要。FFmpeg正在积极发展其实时处理能力,以满足这些应用的需求。
低延迟编码
传统的视频编码通常为了提高压缩效率而引入了较高的延迟,这对于实时应用是不可接受的。FFmpeg提供了多种低延迟编码选项:
// 设置低延迟编码参数
AVCodecContext *codec_ctx = ...;
codec_ctx->flags |= AV_CODEC_FLAG_LOW_DELAY; // 启用低延迟模式
codec_ctx->rc_lookahead = 0; // 禁用前瞻
codec_ctx->gop_size = 0; // 禁用GOP(仅I帧)
codec_ctx->max_b_frames = 0; // 禁用B帧
// 设置编码器特定选项
av_opt_set(codec_ctx->priv_data, "tune", "zerolatency", 0); // 零延迟调优
av_opt_set(codec_ctx->priv_data, "x264opts", "no-scenecut:sliced-threads", 0); // 禁用场景切换,启用切片线程
这些设置可以显著降低编码延迟,但通常会以牺牲一些压缩效率为代价。在实际应用中,需要在延迟和质量之间找到平衡。
实时滤镜处理
实时滤镜处理需要高效的算法和优化的实现:
// 使用实时优化的滤镜
const char *filter_desc = "realtime=1:scale=1280:720:flags=fast_bilinear";
// 使用多线程滤镜处理
AVFilterGraph *graph = avfilter_graph_alloc();
av_opt_set(graph->priv_data, "threads", "4", 0);
// 使用硬件加速滤镜
const char *filter_desc = "scale_cuda=1280:720";
实时滤镜处理的关键是减少每个帧的处理时间,确保处理速度能够跟上输入帧率。这通常需要使用简化的算法、多线程处理和硬件加速等技术。
网络自适应流媒体
网络条件的变化是实时流媒体面临的主要挑战之一。FFmpeg提供了多种工具来适应网络条件的变化:
// 自适应比特率流
const char *filter_desc = "aformat=sample_fmts=fltp:sample_rates=44100:channel_layouts=stereo";
// 动态调整编码参数
AVCodecContext *codec_ctx = ...;
if (network_condition == POOR) {
codec_ctx->bit_rate = 500000; // 降低比特率
codec_ctx->width = 640; // 降低分辨率
codec_ctx->height = 360;
} else if (network_condition == GOOD) {
codec_ctx->bit_rate = 2000000; // 提高比特率
codec_ctx->width = 1280; // 提高分辨率
codec_ctx->height = 720;
}
自适应流媒体技术可以根据网络条件动态调整视频质量,确保流畅的观看体验。这通常需要实时监控网络状况,并相应地调整编码参数。
WebRTC集成
WebRTC是一个开放标准,支持浏览器和移动应用进行实时通信。FFmpeg正在增强其对WebRTC的支持,使其能够更好地与WebRTC生态系统集成:
// 使用WebRTC作为输入
AVFormatContext *format_ctx = NULL;
AVDictionary *options = NULL;
av_dict_set(&options, "protocol_whitelist", "file,udp,rtp", 0);
av_dict_set(&options, "fflags", "nobuffer", 0);
av_dict_set(&options, "flags", "low_delay", 0);
if (avformat_open_input(&format_ctx, "webrtc://url", NULL, &options) != 0) {
printf("Could not open WebRTC input\n");
av_dict_free(&options);
return -1;
}
av_dict_free(&options);
WebRTC集成使FFmpeg能够处理来自浏览器的实时视频流,或向浏览器发送实时视频流,为各种实时应用提供支持。
云原生与分布式处理
随着云计算和容器技术的发展,FFmpeg也在适应这些新的部署模式,提供更好的云原生支持和分布式处理能力。
容器化部署
FFmpeg可以轻松地容器化,以便在云环境中部署:
# 多阶段构建,优化镜像大小
FROM ubuntu:20.04 AS builder
RUN apt-get update && apt-get install -y build-essential yasm nasm
RUN git clone https://git.ffmpeg.org/ffmpeg.git && \
cd ffmpeg && \
./configure --enable-gpl --enable-libx264 --enable-libx265 && \
make -j$(nproc)
FROM ubuntu:20.04 AS runtime
RUN apt-get update && apt-get install -y libx264-163 libx265-179
COPY --from=builder /ffmpeg/ffmpeg /usr/local/bin/
COPY --from=builder /ffmpeg/ffprobe /usr/local/bin/
ENTRYPOINT ["ffmpeg"]
容器化部署提供了更好的可移植性、可扩展性和资源隔离,使FFmpeg能够更好地适应云环境。
微服务架构
FFmpeg可以集成到微服务架构中,提供专门的多媒体处理服务:
# Flask微服务示例
from flask import Flask, request, jsonify
import subprocess
import os
app = Flask(__name__)
@app.route('/transcode', methods=['POST'])
def transcode():
# 获取输入参数
input_file = request.json['input_file']
output_file = request.json['output_file']
options = request.json.get('options', {})
# 构建FFmpeg命令
cmd = ['ffmpeg', '-i', input_file]
# 添加选项
for key, value in options.items():
cmd.extend([f'-{key}', str(value)])
# 添加输出文件
cmd.append(output_file)
# 执行命令
try:
subprocess.run(cmd, check=True)
return jsonify({'status': 'success', 'output_file': output_file})
except subprocess.CalledProcessError as e:
return jsonify({'status': 'error', 'message': str(e)}), 500
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
微服务架构使FFmpeg能够作为专门的服务提供多媒体处理能力,与其他服务协同工作,构建复杂的应用系统。
分布式处理
对于大规模多媒体处理任务,FFmpeg可以与分布式计算框架集成,实现并行处理:
# 使用Dask进行分布式视频处理
import dask
from dask.distributed import Client
import subprocess
import os
# 连接到Dask集群
client = Client('tcp://scheduler:8786')
# 定义处理函数
def process_video(input_file, output_file, options):
cmd = ['ffmpeg', '-i', input_file]
for key, value in options.items():
cmd.extend([f'-{key}', str(value)])
cmd.append(output_file)
try:
subprocess.run(cmd, check=True)
return {'status': 'success', 'output_file': output_file}
except subprocess.CalledProcessError as e:
return {'status': 'error', 'message': str(e)}
# 创建任务列表
tasks = []
for input_file in input_files:
output_file = f'processed/{os.path.basename(input_file)}'
task = dask.delayed(process_video)(input_file, output_file, options)
tasks.append(task)
# 并行执行任务
results = dask.compute(*tasks)
# 处理结果
for result in results:
if result['status'] == 'success':
print(f"Processed: {result['output_file']}")
else:
print(f"Error: {result['message']}")
分布式处理可以显著提高大规模多媒体处理任务的效率,特别是在处理大量视频文件或高分辨率视频时。
无服务器架构
FFmpeg也可以集成到无服务器架构中,提供按需的多媒体处理能力:
# AWS Lambda函数示例
service: ffmpeg-processor
provider:
name: aws
runtime: python3.8
region: us-east-1
functions:
process-video:
handler: handler.process_video
timeout: 300 # 5分钟超时
memorySize: 3008 # 最大内存
layers:
- arn:aws:lambda:us-east-1:145266761615:layer:ffmpeg:4
events:
- s3:
bucket: video-input
event: s3:ObjectCreated:*
rules:
- suffix: .mp4
# Lambda函数处理程序
import subprocess
import os
import boto3
def process_video(event, context):
# 获取输入文件信息
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
# 下载输入文件
input_file = f'/tmp/{os.path.basename(key)}'
s3 = boto3.client('s3')
s3.download_file(bucket, key, input_file)
# 处理视频
output_file = f'/tmp/processed_{os.path.basename(key)}'
cmd = [
'ffmpeg', '-i', input_file,
'-c:v', 'libx264', '-preset', 'fast', '-crf', '23',
'-c:a', 'aac', '-b:a', '128k',
output_file
]
try:
subprocess.run(cmd, check=True)
# 上传输出文件
output_key = f'processed/{os.path.basename(key)}'
s3.upload_file(output_file, 'video-output', output_key)
return {'status': 'success', 'output_key': output_key}
except subprocess.CalledProcessError as e:
return {'status': 'error', 'message': str(e)}
无服务器架构使FFmpeg能够按需处理多媒体内容,无需管理服务器,适合处理不规则的、突发性的多媒体处理任务。
总结:FFmpeg的生态系统与未来展望
FFmpeg的生态系统
FFmpeg不仅仅是一个软件项目,它已经发展成为一个庞大的生态系统,包括核心库、命令行工具、图形界面应用、云服务和各种集成方案。这个生态系统涵盖了从底层编解码到上层应用的完整多媒体处理链。
核心组件
FFmpeg的核心组件包括:
- libavcodec:编解码器库,支持数百种音频和视频编解码器。
- libavformat:格式处理库,支持几乎所有已知的多媒体容器格式。
- libavfilter:滤镜库,提供丰富的音频和视频处理滤镜。
- libavutil:通用工具库,提供数据结构、数学运算、加密等基础功能。
- libswscale:色彩空间转换和图像缩放库。
- libswresample:音频重采样库。
- ffmpeg:命令行工具,提供强大的多媒体处理能力。
- ffplay:简单的媒体播放器。
- ffprobe:多媒体分析工具。
这些核心组件构成了FFmpeg的基础,为各种多媒体处理任务提供了强大的支持。
衍生项目
基于FFmpeg的核心组件,社区开发了众多衍生项目,扩展了FFmpeg的功能和应用场景:
- HandBrake:一个流行的视频转码工具,使用FFmpeg作为后端。
- VLC Media Player:一个跨平台的媒体播放器,使用FFmpeg进行格式支持。
- OBS Studio:一个流行的直播和录制软件,使用FFmpeg进行编码和格式支持。
- Shotcut:一个开源的视频编辑软件,使用FFmpeg进行格式支持和处理。
- Kodi:一个媒体中心软件,使用FFmpeg进行媒体播放。
- Blender:一个3D创作套件,使用FFmpeg进行视频导出。
这些衍生项目展示了FFmpeg的灵活性和可扩展性,它们将FFmpeg的功能包装在用户友好的界面中,使普通用户也能利用FFmpeg的强大功能。
商业应用
FFmpeg也被广泛应用于商业产品中,包括:
- YouTube:使用FFmpeg进行视频转码和处理。
- Netflix:使用FFmpeg进行内容处理和流媒体传输。
- Facebook:使用FFmpeg进行视频上传处理和流媒体传输。
- Vimeo:使用FFmpeg进行视频转码和处理。
- Adobe Premiere Pro:使用FFmpeg进行格式导入和导出。
- Final Cut Pro:使用FFmpeg进行格式支持。
这些商业应用证明了FFmpeg的可靠性和性能,它们在处理海量多媒体内容时依赖FFmpeg的强大功能。
云服务
随着云计算的发展,出现了许多基于FFmpeg的云服务,提供按需的多媒体处理能力:
- AWS Elemental MediaConvert:Amazon提供的视频转码服务,基于FFmpeg。
- Google Cloud Transcoder:Google提供的视频转码服务,使用FFmpeg技术。
- Azure Media Services:Microsoft提供的媒体处理服务,集成FFmpeg。
- Mux:一个专门的视频处理和流媒体API服务,基于FFmpeg。
- Cloudinary:一个图像和视频管理服务,使用FFmpeg进行处理。
这些云服务使开发者无需管理基础设施,就能利用FFmpeg的强大功能进行多媒体处理。
FFmpeg的设计哲学与成功因素
FFmpeg的成功不仅仅在于其功能强大,更在于其独特的设计哲学和开发模式。这些因素共同促成了FFmpeg成为多媒体处理领域的标准工具。
开源与社区驱动
FFmpeg是一个完全开源的项目,采用LGPL或GPL许可证。这种开放性吸引了全球的开发者参与贡献,形成了一个活跃的社区。社区驱动的开发模式使FFmpeg能够快速适应新的技术和标准,不断改进和完善。
模块化设计
FFmpeg采用模块化设计,将功能分解为多个独立的库和组件。这种设计使得FFmpeg具有高度的灵活性和可扩展性,开发者可以根据需要选择使用特定的组件,而不必引入整个框架。
性能优先
FFmpeg从设计之初就将性能作为核心目标。通过汇编优化、多线程处理、硬件加速等技术,FFmpeg实现了卓越的性能,能够处理高分辨率视频和实时流媒体。
跨平台兼容性
FFmpeg支持几乎所有主流的操作系统和CPU架构,包括Windows、Linux、macOS、BSD、Android、iOS等。这种广泛的兼容性使FFmpeg成为跨平台多媒体应用的首选解决方案。
丰富的格式和编解码器支持
FFmpeg支持数百种多媒体格式和编解码器,几乎涵盖了所有已知的标准。这种全面的支持使FFmpeg成为处理多媒体内容的通用工具,无论输入是什么格式,FFmpeg都能处理。
灵活的API和命令行接口
FFmpeg提供了灵活的C API和强大的命令行接口,满足不同用户的需求。开发者可以通过API将FFmpeg集成到自己的应用中,而普通用户可以通过命令行工具完成各种多媒体处理任务。
FFmpeg面临的挑战
尽管FFmpeg取得了巨大的成功,但它也面临着一些挑战,这些挑战将影响其未来的发展方向。
专利与法律问题
多媒体领域充满了专利和知识产权问题。许多编解码器(如H.264、HEVC)都受到专利保护,使用它们需要支付许可费。虽然FFmpeg本身是开源的,但使用某些编解码器可能会涉及专利问题。
为了应对这一挑战,FFmpeg社区开发了免版税的编解码器(如AV1),并积极支持开放标准。然而,专利问题仍然是FFmpeg面临的一个长期挑战。
新兴技术的快速迭代
多媒体技术正在快速发展,新的编解码器、格式和处理技术不断涌现。FFmpeg需要不断更新和改进,以跟上这些技术的发展。这需要大量的开发资源和持续的投入。
硬件加速的复杂性
硬件加速是提高多媒体处理性能的关键,但不同的硬件平台(如Intel、NVIDIA、AMD、ARM)提供不同的硬件加速API,增加了开发和维护的复杂性。FFmpeg需要支持这些不同的API,同时保持代码的可维护性。
实时处理的挑战
随着直播、视频会议和云游戏等实时应用的普及,低延迟处理变得越来越重要。FFmpeg需要进一步优化其实时处理能力,减少编码、解码和滤镜处理的延迟。
机器学习与AI的集成
机器学习和AI技术正在改变多媒体处理的方式,为超分辨率、去噪、增强等任务提供了新的方法。FFmpeg需要更好地集成这些技术,提供更智能、更高效的多媒体处理能力。
FFmpeg的未来展望
尽管面临挑战,FFmpeg的未来仍然充满机遇。以下是一些可能的发展方向:
更好的AI集成
FFmpeg将更深入地集成AI技术,提供更智能的多媒体处理能力。这可能包括:
- 内置AI模型支持:直接在FFmpeg中集成常用的AI模型,无需外部依赖。
- AI优化滤镜:开发基于AI的新滤镜,提供更好的视频增强和修复能力。
- 智能编码决策:使用AI技术优化编码参数,自动适应不同的内容类型和网络条件。
更强的实时处理能力
FFmpeg将进一步优化其实时处理能力,满足低延迟应用的需求:
- 低延迟编解码器:开发或优化专门用于低延迟应用的编解码器。
- 实时优化滤镜:提供更多针对实时应用优化的滤镜,减少处理延迟。
- 更好的网络适应性:增强对网络波动的适应能力,提供更流畅的实时流媒体体验。
更好的云原生支持
FFmpeg将更好地适应云原生环境,提供更高效的分布式处理能力:
- 容器优化:提供更小、更高效的容器镜像,减少资源消耗。
- 微服务集成:提供更好的微服务支持,使FFmpeg能够更容易地集成到微服务架构中。
- 无服务器优化:优化启动时间和资源使用,使FFmpeg更适合无服务器架构。
更广泛的硬件加速支持
FFmpeg将进一步扩展其硬件加速支持,覆盖更多的硬件平台:
- 统一硬件加速API:开发统一的硬件加速API,简化不同硬件平台的适配。
- 新兴硬件支持:支持新兴的硬件平台,如AI加速器、FPGA等。
- 更好的硬件资源管理:优化硬件资源的使用,提高效率和性能。
更强的安全性和隐私保护
随着隐私和安全问题的日益重要,FFmpeg将加强其安全性和隐私保护能力:
- 安全编码实践:采用更严格的安全编码实践,减少安全漏洞。
- 隐私保护滤镜:开发专门用于隐私保护的滤镜,如人脸模糊、语音匿名化等。
- 安全输入验证:增强输入验证和错误处理,防止恶意输入导致的安全问题。
结语:FFmpeg的持久价值
FFmpeg已经从一个简单的个人项目发展成为全球多媒体处理的核心工具。它的成功源于其开放的开发模式、强大的功能、卓越的性能和广泛的兼容性。尽管面临各种挑战,FFmpeg仍然在不断发展和创新,适应新的技术和应用需求。
对于多媒体开发者来说,FFmpeg不仅是一个工具,更是一个学习和创新的平台。通过深入理解FFmpeg的架构和原理,开发者可以掌握多媒体处理的核心技术,构建自己的多媒体应用和服务。
对于普通用户来说,FFmpeg提供了一个强大而灵活的多媒体处理工具,可以满足从简单的格式转换到复杂的视频处理的各种需求。
对于整个多媒体行业来说,FFmpeg已经成为一个基础设施,支撑着从内容创作到分发的整个产业链。它的开放性和标准化促进了行业的创新和发展。
在未来,随着多媒体技术的不断发展和应用场景的不断扩展,FFmpeg将继续发挥其重要作用,成为连接技术创新和实际应用的桥梁。无论是新兴的编解码器、AI技术,还是云原生架构,FFmpeg都将不断适应和进化,保持其在多媒体处理领域的领先地位。
正如FFmpeg的官方标语所说:"FFmpeg is the leading multimedia framework, able to decode, encode, transcode, mux, demux, stream, filter and play pretty much anything that humans and machines have created." 这个描述不仅准确地概括了FFmpeg的当前能力,也预示了其未来的发展方向。在数字多媒体的世界里,FFmpeg将继续扮演着不可或缺的角色,推动着技术的进步和创新。